Administratorzy baz danych dzielą się na tych, którzy wykonują kopie zapasowe i tych, którzy będą robić kopie zapasowe.
W tym artykule opisano najczęstszą kopię zapasową IB 1C przy użyciu narzędzi MS Serwer SQL 2008 R2 wyjaśnia, dlaczego należy to robić w ten, a nie inny sposób, i rozwiewa kilka mitów. Artykuł zawiera wiele linków do dokumentacji MS SQL, ten artykuł jest bardziej przeglądem mechanizmów tworzenia kopii zapasowych niż obszernym przewodnikiem. Ale dla tych, którzy mają do czynienia z tym zadaniem po raz pierwszy, podane są proste instrukcje krok po kroku, które dotyczą prostych sytuacji. Artykuł nie jest przeznaczony dla guru administracji, guru już to wszystko wiedzą, ale zakłada się, że czytelnik jest w stanie samodzielnie zainstalować MS SQL Server i zmusić ten cud wrogiej technologii do stworzenia w swoich trzewiach bazy danych, którą z kolei jest w stanie wymusić przechowywanie danych 1C.
Uważam, że polecenie TSQL BACKUP DATABASE (i jego brat BACKUP LOG) jest zasadniczo jedynym narzędziem do tworzenia kopii zapasowych dla baz danych 1C wykorzystujących MS SQL Server jako DBMS. Dlaczego? Przyjrzyjmy się, jakie metody mamy na ogół:
| Jak | Cienki | Źle | Całkowity |
| Prześlij do dt | Bardzo kompaktowy format. | Formowanie zajmuje dużo czasu, wymaga wyłącznego dostępu, nie zapisuje niektórych nieistotnych danych (takich jak ustawienia użytkownika we wcześniejszych wersjach), wdrażanie zajmuje dużo czasu. | Jest to nie tyle metoda tworzenia kopii zapasowych, co sposób przenoszenia danych z jednego środowiska do drugiego. Idealny do wąskich kanałów. |
| Kopiowanie plików mdf i ldf | Bardzo przejrzysty sposób dla początkujących administratorów. | Wymaga zwolnienia plików bazy danych z blokady, a jest to możliwe, jeśli baza danych jest wyłączona (komenda take offline menu kontekstowe), rozłączony (odłącz) lub po prostu zatrzymał serwer. Oczywiście użytkownicy nie będą mogli w tym czasie pracować. | Zastosowanie tej metody ma sens wtedy i tylko wtedy, gdy awaria już wystąpiła, aby przy próbie przywrócenia móc przynajmniej wrócić do opcji, od której rozpoczęto przywracanie. |
| Tworzenie kopii zapasowych przy użyciu systemu operacyjnego lub hiperwizora | Wygodny sposób dla środowisk deweloperskich i testowych. | Nie zawsze przyjazny dla integralności danych. zasobochłonny sposób. | Może mieć ograniczone zastosowanie do rozwoju. Nie ma to praktycznego znaczenia w środowisku żywnościowym. |
| Kopia zapasowa przy użyciu MS SQL | Nie wymaga przestojów. Pozwala przywrócić spójny stan do dowolnego momentu, jeśli zadbasz o to z wyprzedzeniem. Idealnie zautomatyzowany. Oszczędność czasu i innych zasobów. | Niezbyt zwarty. Nie każdy wie, jak korzystać z tej metody w niezbędnym zakresie. | Dla środowisk produkcyjnych - główne narzędzie. |
Główne trudności podczas korzystania z backupu za pomocą wbudowanych narzędzi MS SQL wynikają z elementarnego niezrozumienia zasad pracy. Po części tłumaczy się to wielkim lenistwem, po części brakiem prostego i zrozumiałego wyjaśnienia na poziomie „gotowych przepisów” (hmm, powiedzmy, nie widziałem), a sytuację pogarszają nawet mitologiczne rady "pod-guru" na forach. Nie wiem, co zrobić z lenistwem, ale postaram się wyjaśnić podstawy tworzenia kopii zapasowych.
Dawno temu w odległej galaktyce istniał taki produkt inżynierii i myśli księgowej jak 1C: Enterprise 7.7. Najwyraźniej ze względu na fakt, że pierwsze wersje 1C:Enterprise zostały opracowane z myślą o wykorzystaniu popularnego formatu plików dbf, jego wersja SQL nie przechowywała w bazie danych wystarczającej ilości informacji, aby uznać tworzenie kopii zapasowej MS SQL za kompletną, a nawet przy każdej zmianie w strukturze, warunków pracy modelu pełnego odzyskiwania, więc trzeba było stosować różne sztuczki, aby system kopii zapasowych spełniał swoją główną funkcję. Ale odkąd pojawiła się wersja 8, administratorzy baz danych wreszcie mogli się zrelaksować. Regularne narzędzia do tworzenia kopii zapasowych pozwalają na stworzenie kompletnego i kompletnego systemu kopii zapasowych. Jedynie log rejestracji i kilka drobiazgów jak ustawienie pozycji formularzy (w starszych wersjach) nie są uwzględniane w backupie, ale ta utrata tych danych nie wpływa na funkcjonalność systemu, choć na pewno jest poprawna i przydatna wykonać kopie zapasowe dziennika rejestracji.
Dlaczego w ogóle potrzebujemy kopii zapasowej? Hm. Na pierwszy rzut oka to dziwne pytanie. Cóż, pewnie po pierwsze, żeby móc zainstalować kopię systemu, a po drugie, aby przywrócić system w przypadku awarii? Zgadzam się co do pierwszego, ale drugie spotkanie to mit pierwszej kopii zapasowej.
Kopia zapasowa to ostatnia linia obrony integralności systemu. Jeśli administrator bazy danych musi odtworzyć system produktu z kopii zapasowych, oznacza to, że z dużym prawdopodobieństwem popełniono wiele błędów w organizacji pracy. Nie można traktować backupu jako głównego sposobu zapewnienia integralności danych, nie, to raczej system gaśniczy. Wymagany jest system przeciwpożarowy. Musi być skonfigurowany, przetestowany i sprawny. Ale jeśli to zadziałało, to samo w sobie jest poważną sytuacją awaryjną z wieloma negatywnymi konsekwencjami.
Aby kopia zapasowa była wykorzystywana wyłącznie do celów „pokojowych”, użyj innych środków zapewniających wydajność:
W zależności od wymagań dostępności systemu i budżetu przeznaczonego na te cele, całkiem możliwe jest wybranie rozwiązań, które zmniejszą przestoje i przywracanie po awarii o 1-2 rzędy wielkości. Technologii dostępności nie trzeba się bać: są one na tyle proste, że można się ich nauczyć w kilka dni z podstawową znajomością MS SQL.
Ale mimo wszystko tworzenie kopii zapasowych jest nadal konieczne. To ten sam spadochron zapasowy, którego możesz użyć, gdy wszystkie inne sposoby ucieczki zawiodą. Ale, jak prawdziwy spadochron rezerwowy, do tego:
Dane w MS SQL są zwykle przechowywane w plikach danych (dalej FD nie jest powszechnie używanym skrótem, w tym artykule będzie jeszcze kilka niezbyt częstych skrótów) z rozszerzeniami mdf lub ndf. Oprócz tych plików istnieją również dzienniki transakcji (LT), które są przechowywane w plikach z rozszerzeniem ldf. Często zdarza się, że początkujący administratorzy zachowują się nieodpowiedzialnie i nonszalancko w stosunku do VT, zarówno pod względem wydajności, jak i niezawodności pamięci masowej. To bardzo poważny błąd. W rzeczywistości wręcz przeciwnie, jeśli istnieje niezawodnie działający system tworzenia kopii zapasowych i można przeznaczyć dużo czasu na przywrócenie systemu, można przechowywać dane na szybkiej, ale wyjątkowo zawodnej macierzy RAID-0, ale wtedy należy przechowywać VT na oddzielnym niezawodnym i produktywnym zasobie (chociaż byłby na RAID-1). Dlaczego? Przyjrzyjmy się bliżej. Natychmiast zrób rezerwację, że prezentacja jest nieco uproszczona, ale wystarczająca do wstępnego zrozumienia.
FD przechowuje dane na stronach po 8 kilobajtów (które są łączone w zakresy po 64 kilobajty, ale nie jest to konieczne). MSSQL nie gwarantujeże zaraz po wykonaniu polecenia zmiany danych zmiany te wpadną do DF. Nie, po prostu strona w pamięci jest oznaczona jako „wymagająca zapisania”. Jeśli serwer ma wystarczającą ilość zasobów, to wkrótce te dane znajdą się na dysku. Co więcej, serwer działa „optymistycznie” i jeśli te zmiany wystąpią w transakcji, to równie dobrze mogą dostać się na dysk, zanim transakcja zostanie zatwierdzona. Czyli w ogólnym przypadku aktywna praca FD zawiera rozproszone fragmenty niedokończonych danych i niekompletnych transakcji, dla których nie wiadomo, czy zostaną anulowane, czy zatwierdzone. Istnieje specjalne polecenie „PUNKT KONTROLNY”, które mówi serwerowi, aby „w tej chwili” wyrzucił wszystkie niezapisane dane na dysk, ale zakres tego polecenia jest dość specyficzny. Wystarczy powiedzieć, że 1C go nie używa (nie spotkałem się z tym) i rozumiem, że podczas pracy FD zwykle nie jest w spójnym stanie.
Aby poradzić sobie z tym chaosem, potrzebujemy tylko VT. Zapisane są w nim następujące wydarzenia:
Wszystkie te informacje są zapisywane ze wskazaniem identyfikatora transakcji, w której wystąpiła i w wystarczającej objętości, aby zrozumieć, jak przejść ze stanu przed tą operacją do stanu po tej operacji i odwrotnie (wyjątkiem jest model odzyskiwania z logowaniem masowym) .
Ważne jest, aby te informacje były natychmiast zapisywane na dysku. Dopóki informacje nie zostaną zapisane w VT, polecenie nie jest uważane za wykonane. W normalnej sytuacji, gdy rozmiar VT jest wystarczający i gdy nie jest bardzo pofragmentowany, rekordy są do niego zapisywane sekwencyjnie w małych rekordach (niekoniecznie wielokrotnościach 8 kb). Do dziennika transakcji trafiają tylko te dane, które są rzeczywiście potrzebne do odzyskania. W szczególności Nie otrzymywane są informacje o tym, jaki tekst żądania doprowadził do modyfikacji, jaki plan wykonania miał ten wniosek, jaki użytkownik go uruchomił oraz inne informacje, które są niepotrzebne do odzyskania. Pewne wyobrażenie o strukturze danych dziennika transakcji może dać zapytanie
Wybierz * z::fn_dblog(null,null)
W związku z faktem, że dyski twarde znacznie wydajniej pracują przy zapisie sekwencyjnym niż przy chaotycznym strumieniu poleceń odczytu i zapisu oraz ze względu na to, że polecenia SQL będą czekać do końca zapisu do VT, nasuwa się następujące zalecenie:
Jeśli istnieje choćby najmniejsza możliwość, to w środowisku produkcyjnym VT powinny znajdować się na oddzielnych (od wszystkiego innego) nośnikach fizycznych, najlepiej z minimalnym czasem dostępu do zapisu sekwencyjnego iz maksymalną niezawodnością. Dla proste systemy RAID-1 jest w porządku.
Jeśli transakcja zostanie anulowana, serwer przywróci wszystkie wprowadzone zmiany do poprzedniego stanu. Dlatego
Anulowanie transakcji w MS SQL Server zwykle trwa porównywalnie do całkowitego czasu trwania operacji modyfikacji danych samej transakcji. Staraj się nie anulować transakcji lub zdecyduj się na anulowanie tak wcześnie, jak to możliwe.
Jeśli serwer z jakiegoś powodu nieoczekiwanie przestanie działać, to po ponownym uruchomieniu przeanalizuje, które dane w FD nie odpowiadają stanowi spójnemu (transakcje niezarejestrowane, ale zatwierdzone oraz transakcje zarejestrowane, ale anulowane) i dane te zostaną poprawione. Dlatego jeśli na przykład zacząłeś odbudowywać indeksy dużej tabeli i zrestartowałeś serwer, to po ponownym uruchomieniu cofnięcie tej transakcji zajmie sporo czasu i nie ma sposobu, aby przerwać ten proces.
Co się stanie, gdy JT osiągnie koniec pliku? To proste - jeśli na początku jest wolne miejsce, to zacznie zapisywać do wolnego miejsca na początku pliku, aż zajęte miejsce. Jak zapętlona taśma magnetyczna. Jeśli na początku nie ma miejsca, serwer zwykle będzie próbował rozszerzyć plik dziennika transakcji, podczas gdy dla serwera nowy przydzielony fragment to nowy wirtualny plik dziennika transakcji, którego może być wiele w fizycznym pliku transakcji, ale to nie wystarczy na kopię zapasową. Jeśli serwerowi nie uda się rozszerzyć pliku (brakuje miejsca na dysku lub w ustawieniach zabronione jest rozszerzanie VT), wówczas bieżąca transakcja zostanie anulowana z błędem 9002.
Ups. A co należy zrobić, aby zawsze było miejsce w ZhT? W tym miejscu dochodzimy do systemu tworzenia kopii zapasowych i modeli odzyskiwania. Aby anulować transakcje i przywrócić właściwy stan serwera w przypadku nagłego wyłączenia, konieczne jest przechowywanie rekordów w LT począwszy od początku najwcześniej otwartej transakcji. To minimum jest zapisywane i przechowywane w JT Koniecznie. Niezależnie od pogody, ustawień serwera i chęci administratora. Serwer nie może pozwolić na brak tych informacji. Dlatego jeśli otworzysz transakcję w jednej sesji i wykonasz inne czynności w innych, dziennik transakcji może się nieoczekiwanie zakończyć. Najwcześniejszą transakcję można zidentyfikować za pomocą polecenia DBCC OPENTRAN. Ale to tylko niezbędne minimum informacji. To, co będzie dalej, zależy od modele odzyskiwania. W SQL Server są trzy:
Istnieje kilka mitów związanych z modelami odzyskiwania.
Model rejestrowany zbiorczo dla baz danych 1C jest prawie bezcelowy w użyciu, więc nie będziemy go dalej rozważać. Ale wybór między pełnym a prostym zostanie rozważony bardziej szczegółowo w następnej części.
Istnieją trzy rodzaje kopii zapasowych w zależności od typu formacji:
Nie daj się zmylić: model pełnego odzyskiwania i pełna kopia zapasowa to zasadniczo różne rzeczy. Aby ich nie mylić, poniżej będę używał angielskich terminów dla modelu odzyskiwania i rosyjskich dla rodzajów kopii zapasowych.
Kopia pełna i różnicowa działają tak samo w trybie prostym i pełnym. W Simple całkowicie brakuje kopii zapasowej dziennika transakcji.
Umożliwia przywrócenie stanu bazy danych do określonego punktu w czasie (do tego, w którym rozpoczęto tworzenie kopii zapasowej). Składa się ze stronicowanej kopii używanej części plików danych oraz aktywnego fragmentu dziennika transakcji na czas tworzenia kopii zapasowej.
Przechowuje strony danych, które uległy zmianie od ostatniej pełnej kopii zapasowej. Podczas przywracania należy najpierw przywrócić pełną kopię zapasową (w trybie NORECOVERY przykłady zostaną podane poniżej), następnie można zastosować dowolną z kolejnych kopii różnicowych do wynikowego „pustego”, ale oczywiście tylko tych wykonanych przed następnym pełna kopia zapasowa. Może to znacznie zmniejszyć głośność miejsca na dysku do przechowywania kopii zapasowej.
Ważne punkty:
Zawiera kopię VT na określony okres. Zwykle od momentu ostatniego RKZHT do powstania obecnego RKZHT. RCRT pozwala na przywrócenie stanu w dowolnym kolejnym punkcie czasowym, zawartym w interwale przywróconej kopii zapasowej, od kopii przywróconej w trybie NORECOVERY do dowolnego punktu w czasie zawartego w okresie przywróconej kopii RT. Podczas tworzenia kopii zapasowej o standardowych parametrach miejsce w pliku dziennika transakcji zostaje zwolnione (do momentu ostatniej otwartej transakcji).
Oczywiste jest, że RKZhT nie ma sensu w modelu Simple (wtedy VT zawiera tylko informacje od momentu ostatniej niezamkniętej transakcji).
Podczas korzystania z RKZHT powstaje ważna koncepcja - ciągły łańcuch RKZhT. Łańcuch ten może zostać przerwany albo przez utratę niektórych kopii zapasowych tego łańcucha, albo przez przełączenie bazy danych na Prostą i odwrotnie.
Ostrzeżenie: zestaw RCST jest zasadniczo bezużyteczny, chyba że jest ciągłym łańcuchem, a czas rozpoczęcia ostatniej udanej pełnej lub różnicowej kopii zapasowej musi być równy wewnątrz okres tego łańcucha.
Powszechne nieporozumienia i mity:
Niech będzie baza danych o pojemności 1000 GB. Każdego dnia baza powiększa się o 2 GB, zmieniając przy tym 10 GB starych danych. Wykonano następujące kopie zapasowe
Za pomocą tego zestawu możemy przywrócić dane o godzinie 0:00 w dowolnym dniu od 1 lutego do 14 lutego. Aby to zrobić, musimy pobrać pełną kopię F1 na tydzień 1-7 lutego lub pełną kopię F2 na 8-14 lutego, przywrócić ją w trybie NORECOVERY, a następnie zastosować kopię różnicową z żądanego dnia.
Załóżmy, że mamy taki sam zestaw pełnych i różnicowych kopii zapasowych, jak w poprzednim przykładzie. Oprócz tego istnieją następujące RKZHT:
Notatka:
W najprostszym przypadku musimy przywrócić:
Najpierw zostanie przywrócona F2, potem D2.2, potem RKZHT 6 do 13:13:13 10 lutego. Ale istotną zaletą modelu Full jest to, że mamy wybór - użyć najnowszej kopii pełnej lub różnicowej, albo NIE najnowszej. Na przykład, jeśli odkryto, że kopia D2.2 jest uszkodzona i musimy przywrócić do momentu sprzed 13:13:13 10 lutego, to dla modelu Simple oznaczałoby to, że możemy przywrócić dane tylko do chwila D2.1. Z Full - "DON" T PANIC" mamy następujące opcje:
Jak widać, pełny model daje nam większy wybór.
A teraz wyobraź sobie, że jesteśmy bardzo przebiegli. A na kilka dni przed awarią (13:13:13 10 lutego) wiemy, że będzie awaria. Przywracamy bazę danych z pełnej kopii zapasowej na sąsiednim serwerze, pozostawiając możliwość rollowania kolejnych stanów z kopiami różnicowymi lub RCRT, czyli pozostawionymi w trybie NORECOVERY. I za każdym razem bezpośrednio po utworzeniu RKZhT stosujemy go do tej bazy rezerwowej, pozostawiając ją w trybie NORECOVERY. Wow! Dlaczego, teraz przywrócenie bazy danych zajmie nam tylko 10-15 minut, zamiast przywracania ogromnej bazy danych! Gratulacje, opracowaliśmy na nowo mechanizm wysyłki kłód, który jest jednym ze sposobów na skrócenie przestojów. Jeśli przesyłasz dane w ten sposób nie raz na jakiś czas, ale stale, to dublowanie się okaże, a jeśli baza źródłowa czeka, aż baza lustrzana zostanie zaktualizowana, to jest to dublowanie synchroniczne, jeśli nie czeka, to asynchroniczne.
Więcej o narzędziach wysokiej dostępności przeczytasz w pomocy:
Możesz bezpiecznie pominąć tę sekcję, jeśli znudziła Cię teoria i masz ochotę wypróbować ustawienia kopii zapasowej.
1C:Enterprise w rzeczywistości nie wie, jak pracować z grupami plików. Jest jedna grupa plików i to wszystko. W rzeczywistości programista lub administrator bazy danych MS SQL jest w stanie umieścić niektóre tabele, indeksy, a nawet fragmenty tabel i indeksów w oddzielnych grupach plików (w najprostszej wersji w pojedyncze pliki). Jest to konieczne albo w celu przyspieszenia dostępu do niektórych danych (umieszczenia ich na bardzo szybkich nośnikach), albo odwrotnie, poświęcając szybkość, aby umieścić je na tańszych nośnikach (np. mało używane, ale obszerne dane). Podczas pracy z grupami plików możliwe jest tworzenie ich kopii zapasowych osobno, a także przywracanie ich osobno, ale należy wziąć pod uwagę, że wszystkie grupy plików będą musiały zostać „dogonione” do jednej chwili przez rzucenie RKZHT.
Jeśli osoba kontroluje umieszczanie danych w różnych grupach plików, to gdy w grupie plików znajduje się kilka plików, MS SQL Server umieszcza na nich dane niezależnie (przy równej liczbie plików spróbuje równomiernie). Z punktu widzenia aplikacji służy to do zrównoleglania operacji we/wy. A jeśli chodzi o kopie zapasowe, jest jeszcze jedna kwestia. W przypadku bardzo dużych baz danych w erze „przed SQL 2008” typowym problemem było przydzielenie ciągłego okna dla pełnej kopii zapasowej, a dysk docelowy dla tej kopii zapasowej mógł po prostu do niego nie pasować. najbardziej w prosty sposób w tym przypadku było to wykonanie kopii zapasowej każdego pliku (lub grupy plików) w jego własnym oknie. Teraz, wraz z aktywnym rozpowszechnianiem się kompresji kopii zapasowych, problem ten stał się mniejszy, ale nadal można pamiętać o tej technice.
MS SQL Server 2008 ma funkcję super-mega-ultra. Od teraz kopie zapasowe mogą być kompresowane w locie. Zmniejsza to rozmiar kopii zapasowej bazy danych 1C o 5-10 razy. A biorąc pod uwagę, że zwykle wydajność podsystem dyskowy jest wąskim gardłem DBMS, to nie tylko zmniejsza koszty przechowywania, ale także potężne przyspieszenie tworzenia kopii zapasowych (chociaż obciążenie procesorów wzrasta, ale zwykle moc procesora jest wystarczająca na serwerze DBMS).
O ile w wersji 2008 ta funkcja była dostępna tylko dla wersji Enterprise (która jest bardzo droga), o tyle w 2008 R2 ta funkcja została udostępniona wersji Standard, co jest bardzo przyjemne.
Ustawienia kompresji nie zostały omówione w poniższych przykładach, ale zdecydowanie zalecam korzystanie z kompresji kopii zapasowej, chyba że istnieje konkretny powód, aby ją wyłączyć.
W rzeczywistości kopia zapasowa to nie tylko plik, to raczej złożony kontener, w którym można przechowywać wiele kopii zapasowych. To podejście ma bardzo starą historię (osobiście obserwowałem je od wersji 6.5), ale w tej chwili nie ma poważnych powodów, aby administratorzy „zwykłych” baz danych, zwłaszcza baz danych 1C, nie stosowali zasady „jedna kopia zapasowa - jeden plik” podejście . Dla ogólnego rozwoju przydatne jest przestudiowanie możliwości umieszczania kilku kopii zapasowych w jednym pliku, ale najprawdopodobniej nie będziesz musiał z niej korzystać (lub jeśli musisz, to sortowanie blokad niedoszłego administratora, który użył tę okazję nieumiejętnie).
SQL Server ma jeszcze jedną wspaniałą cechę. Możliwe jest tworzenie kopii zapasowej równolegle do kilku odbiorników. Jako prosty przykład możesz zrzucić jedną kopię na dysk lokalny i jednocześnie zrzucić na zasób sieciowy. Kopia lokalna jest wygodna, ponieważ przywracanie z niej jest znacznie szybsze, podczas gdy kopia zdalna jest w stanie znacznie lepiej przetrwać fizyczne zniszczenie głównego serwera bazy danych.
Dosyć teorii. Czas udowodnić w praktyce, że cała ta kuchnia działa.
Ta sekcja jest zbudowana w formie gotowych przepisów wraz z objaśnieniami. Ta sekcja jest bardzo nudna i długa ze względu na zdjęcia, więc możesz ją pominąć.
Od razu pojawia się pytanie, co jeszcze jest potrzebne? Wydaje się, że wszystko zostało właśnie ustawione i wszystko działa jak w zegarku? Po co męczyć się z różnymi rodzajami skryptów? Plany serwisowe nie zezwalają na:
Poniżej przedstawiono typowe polecenia tworzenia kopii zapasowych
Pełna kopia zapasowa z nadpisaniem istniejącego pliku (jeśli istnieje) i weryfikacją sum kontrolnych stron przed zapisem. Podczas tworzenia kopii zapasowej liczony jest każdy procent postępu
KOPIA ZAPASOWA BAZY DANYCH NA DYSKU = N"C:\Backup\mydb.bak" Z INIT, FORMAT, STATS = 1, SUMA KONTROLNA
Podobnie - kopia różnicowa
KOPIA ZAPASOWA BAZY DANYCH NA DYSKU = N"C:\Backup\mydb.diff" Z MECHANIZM RÓŻNICOWY, INIT, FORMAT, STATYSTYKI = 1, SUMA KONTROLNA
Kopia zapasowa dziennika transakcji
DZIENNIK KOPII ZAPASOWEJ NA DYSKU = N"C:\Backup\mydb.trn" Z INIT, FORMAT
Często wygodnie jest wykonać nie jedną kopię zapasową na raz, ale dwie. Na przykład, jeden może leżeć lokalnie na serwerze (tak, aby był pod ręką), a drugi jest od razu formowany w fizycznie odległy i chroniony przed niekorzystnymi warunkami magazyn:
ZAPASOWA BAZY DANYCH NA DYSEK = N"C:\Backup\mydb.bak", LUSTRO DO DYSK = N"\\bezpieczny-serwer\backup\mydb.bak" Z INIT, FORMATEM
Ważny punkt, który jest często pomijany: użytkownik, w ramach którego uruchamiany jest proces MSSQL Server, musi mieć dostęp do zasobu „\\safe-server\backup\”, w przeciwnym razie kopiowanie się nie powiedzie. Jeśli MSSQL Server działa w imieniu systemu, dostęp musi być przyznany użytkownikowi domeny „nazwa_serwera$”, ale nadal lepiej jest poprawnie skonfigurować MS SQL do działania w imieniu specjalnie utworzonego użytkownika.
Jeśli nie określisz MIRROR TO , to nie będą to 2 kopie lustrzane, ale jedna kopia podzielona na 2 pliki, zgodnie z zasadą paskowania. I każdy z nich z osobna będzie bezużyteczny.
Serwery bazodanowe są jednymi z kluczowych w każdej organizacji. To one przechowują informacje i udostępniają dane wyjściowe na żądanie, a niezwykle ważne jest, aby w każdej sytuacji zachować bazę danych. Podstawowa dystrybucja zwykle zawiera niezbędne narzędzia, ale administrator, który nie miał wcześniej styczności z bazą danych, będzie musiał przez jakiś czas radzić sobie ze specyfiką pracy, aby zapewnić automatyzację.
Na początek zastanówmy się, jakie są ogólnie kopie zapasowe. Serwer bazy danych nie jest zwykłą aplikacją desktopową i aby zapewnić realizację wszystkich właściwości ACID (Atomic, Consistency, Isolated, Durable) stosuje się szereg technologii, dlatego tworzenie i odtwarzanie bazy danych z archiwum ma swoje własne cechy. Istnieją trzy różne podejścia do tworzenia kopii zapasowych danych, z których każde ma swoje zalety i wady.
Dzięki logicznej lub SQLowej kopii zapasowej (pg_dump, mysqldump, SQLCMD) tworzony jest natychmiastowy snapshot zawartości bazy danych z uwzględnieniem integralności transakcyjnej i zapisywany jako plik z poleceniami SQL (można wybrać całą bazę danych lub poszczególne tabele), za pomocą których można odtworzyć bazę danych na innym serwerze. Zapisywanie i przywracanie wymaga czasu (zwłaszcza w przypadku dużych baz danych), dlatego bardzo często operacja ta nie może zostać wykonana i jest wykonywana przy minimalnym obciążeniu (na przykład w nocy). Podczas przywracania administrator będzie musiał wykonać kilka poleceń, aby przygotować wszystko, co niezbędne (utworzyć pustą bazę danych, Konta I tak dalej).
Fizyczna kopia zapasowa (poziom system plików) - kopiuje pliki, których DBMS używa do przechowywania danych w bazie danych. Ale proste kopiowanie ignoruje blokady i transakcje, które mogą być nieprawidłowo przechowywane i łamane. Jeśli spróbujesz załączyć ten plik, będzie on w niespójnym stanie i spowoduje błędy. Aby uzyskać aktualną kopię zapasową, baza danych musi zostać zatrzymana (czas przestoju można skrócić, używając dwukrotnie rsync - najpierw na działającej, a następnie na zatrzymanej). Wada tej metody jest oczywista - nie można przywrócić niektórych danych, tylko całą bazę danych. Podczas uruchamiania bazy danych przywróconej z archiwum systemu plików konieczne będzie sprawdzenie integralności. Stosowane są tutaj różne technologie wspomagające. Na przykład w PostgreSQL dzienniki WAL (Write Ahead Logs) i specjalna funkcja(Point in Time Recovery – PITR), która umożliwia powrót do określonego stanu bazy danych. Z ich pomocą trzeci scenariusz jest łatwy do zrealizowania, gdy kopia zapasowa na poziomie systemu plików jest połączona z kopią zapasową pliku WAL. Najpierw przywracamy kopie zapasowe plików systemu plików, a następnie za pomocą WAL aktualizujemy bazę danych. Jest to nieco bardziej skomplikowane podejście do administracji, ale nie ma problemów z integralnością bazy danych i przywracaniem baz danych do określonego czasu.
Kopię logiczną stosuje się w przypadkach, gdy konieczne jest jednorazowe wykonanie pełnej kopii bazy danych lub w codziennym użytkowaniu utworzenie kopii nie zajmuje dużo czasu ani miejsca. Gdy rozładowywanie baz danych zajmuje dużo czasu, należy zwrócić uwagę na fizyczną archiwizację.
Licencja: GNU GPL
Obsługiwany DBMS: PostgreSQL
PostgreSQL obsługuje fizyczne i logiczne możliwości tworzenia kopii zapasowych, dodając kolejną warstwę WAL (patrz pasek boczny), którą można nazwać ciągłą kopią zapasową. Jednak zarządzanie kilkoma serwerami przy użyciu standardowych narzędzi nie jest zbyt wygodne nawet dla doświadczonego administratora, aw przypadku awarii liczą się sekundy.
Barman (backup and recovery manager) jest wewnętrznym rozwinięciem 2ndQuadrant, firmy świadczącej usługi w oparciu o PostgreSQL. Zaprojektowany do fizycznego tworzenia kopii zapasowych PostgreSQL (logiczny nie obsługuje), archiwizacji WAL i szybka rekonwalescencja po awariach. Obsługuje zdalne tworzenie kopii zapasowych i przywracanie wielu serwerów, odzyskiwanie do punktu w czasie (PITR), zarządzanie WAL. SSH służy do kopiowania i wydawania poleceń do zdalnego hosta, synchronizacja i tworzenie kopii zapasowych za pomocą rsync pozwala zmniejszyć ruch. Barman integruje się również z standardowe narzędzia bzip2, gzip, tar i tym podobne. W zasadzie możesz użyć dowolnego programu do kompresji i archiwizacji, integracja nie zajmie dużo czasu. Zaimplementowano różne funkcje serwisowe i diagnostyczne, które pozwalają monitorować stan usług i dostosowywać przepustowość. Obsługiwane są skrypty Pre/Post.
Barman jest napisany w Pythonie, a zasady tworzenia kopii zapasowych są zarządzane za pomocą przyjaznego pliku INI barman.conf, który może znajdować się w /etc lub w katalogu domowym użytkownika. Przesyłka zawiera gotowy szablon ze szczegółowymi komentarzami w środku. Działa tylko na systemach * nix. Aby zainstalować na RHEL, CentOS i Scientific Linux, musisz podłączyć EPEL - repozytorium zawierające dodatkowe pakiety. Użytkownicy Debiana/Ubuntu mają do dyspozycji oficjalne repozytorium:
$ sudo apt-get install barman
Nie zawsze w repozytorium Ostatnia wersja, aby go zainstalować, będziesz musiał odwołać się do tekstów źródłowych. Istnieje kilka zależności, a proces jest łatwy do zrozumienia.
Licencja: BSD
Obsługiwany DBMS: MySQL
Wraz z MySQL dostarczane są narzędzia mysqldump i mysqlhotcopy, które umożliwiają łatwe tworzenie zrzutu bazy danych, są one dobrze udokumentowane, aw Internecie można znaleźć dużą liczbę gotowych przykładów i nakładek. Te ostatnie pozwalają początkującemu szybko zabrać się do pracy. Sypex Dumper to skrypt PHP, który umożliwia łatwe tworzenie i przywracanie kopii bazy danych Dane MySQL. Zaprojektowany do pracy z dużymi bazami danych, jest bardzo szybki, przejrzysty i łatwy w użyciu. Wie, jak pracować z obiektami MySQL - widokami, procedurami, funkcjami, wyzwalaczami i zdarzeniami.
Kolejną zaletą, w przeciwieństwie do innych narzędzi, które konwertują do UTF-8 podczas eksportu, jest to, że Dumper eksportuje w natywnym kodowaniu. Wynikowy plik zajmuje mniej miejsca, a sam proces jest szybszy. Jeden zrzut może zawierać obiekty z różnymi kodowaniami. Ponadto łatwo jest importować / eksportować w kilku etapach, zatrzymując proces podczas ładowania. Po ponownym uruchomieniu procedura rozpocznie się od miejsca, w którym została przerwana. Dostępne są cztery opcje odzyskiwania:
Obsługuje kompresję kopii (gzip lub bzip2), automatyczne usuwanie starych kopii zapasowych, przeglądanie zawartości pliku zrzutu, przywracanie tylko struktury tabel. Dostępne są również funkcje serwisowe do zarządzania bazą danych (tworzenie, usuwanie, sprawdzanie, przywracanie bazy, optymalizacja, czyszczenie tabel, praca z indeksami itp.), a także menadżer plików pozwalający na kopiowanie plików na serwer.

Zarządzanie odbywa się za pomocą przeglądarki internetowej, interfejs AJAX jest zlokalizowany od razu po wyjęciu z pudełka i sprawia wrażenie pracy z aplikacją komputerową. Możliwe jest również uruchamianie zadań z konsoli i zgodnie z harmonogramem (przez cron).
Do działania Dumper potrzebny będzie klasyczny serwer L|WAMP, instalacja jest wspólna dla wszystkich aplikacji napisanych w PHP (kopiuj pliki i ustaw uprawnienia) i nie będzie trudna nawet dla początkującego. Projekt zawiera szczegółową dokumentację i samouczki wideo pokazujące, jak pracować z Sypex Dumper.
Istnieją dwie edycje: Sypex Dumper (bezpłatny) i Pro (10 USD). Drugi ma więcej funkcji, wszystkie różnice są wymienione na stronie.
Licencja:
Obsługiwany DBMS: Serwer MSSQL
MS SQL Server jest jednym z popularnych rozwiązań, dlatego jest dość powszechny. Zadanie tworzenia kopii zapasowej jest tworzone przy użyciu SQL Server Management Studio, samego Transact-SQL i poleceń cmdlet modułu SQL PowerShell (Backup-SqlDatabase). Na stronie MS można znaleźć ogromną ilość dokumentacji, która pozwala zrozumieć proces. Dokumentacja, choć kompletna, jest bardzo konkretna, a informacje w internecie często sobie przeczą. Początkujący naprawdę będzie musiał najpierw poćwiczyć, „wypełniając swoją rękę”, dlatego pomimo wszystkiego, co zostało powiedziane, zewnętrzni programiści mają miejsce na odwrócenie się. Oprócz Darmowa wersja SQL Server Express nie oferuje wbudowanych narzędzi do tworzenia kopii zapasowych. Po więcej wczesne wersje MS SQL (sprzed 2008) można znaleźć darmowe narzędzia, takie jak SQL Server backup, ale większość tych projektów została już skomercjalizowana, choć często oferują wszystkie funkcjonalności za symboliczną kwotę.

Na przykład rozwój SQL Backup And FTP oraz One-Click SQL Restore jest zgodny z zasadą „ustaw i zapomnij”. Dzięki bardzo prostemu i intuicyjnemu interfejsowi pozwalają tworzyć kopie baz danych MS SQL Server (w tym Express) i Azure, zapisywać zaszyfrowane i skompresowane pliki do FTP i usługi w chmurze(Dropbox, Box, dysk Google, MS SkyDrive lub Amazon S3), wynik można zobaczyć natychmiast. Możliwe jest uruchomienie procesu zarówno ręcznie, jak i zgodnie z harmonogramem, wysłanie wiadomości e-mail o wyniku zadania, uruchomienie skryptów użytkownika.
Obsługiwane są wszystkie opcje tworzenia kopii zapasowych: pełna, różnicowa, dziennik transakcji, kopiowanie folderu z plikami i wiele więcej. Stare kopie zapasowe są usuwane automatycznie. Aby połączyć się z wirtualnym hostem, używane jest SQL Management Studio, chociaż może to być dopracowane i nie będzie działać we wszystkich takich konfiguracjach. Do pobrania dostępnych jest pięć wersji - od Bezpłatny fantazyjnemu Prof Lifetime (tylko 149 USD w momencie pisania tego tekstu). Wystarczy darmowa funkcjonalność małe sieci, w którym zainstalowany jest jeden lub dwa serwery SQL, wszystkie podstawowe funkcje są aktywne. Liczba kopii zapasowych baz danych, możliwość wysyłania plików na Dysk Google i SkyDrive oraz szyfrowanie plików są ograniczone. Interfejs, choć nie zlokalizowany, jest bardzo prosty i zrozumiały nawet dla początkującego. Wystarczy połączyć się z serwerem SQL, po czym zostanie wyświetlona lista baz danych, należy zaznaczyć te, które są nam potrzebne, skonfigurować dostęp do zdalnych zasobów oraz określić czas wykonania zadania. A wszystko to w jednym oknie.
Ale jest jedno „ale”. Sam program nie jest przeznaczony do przywracania archiwów. Aby to zrobić, oferowane jest oddzielne bezpłatne narzędzie One-Click SQL Restore, które również rozumie format utworzony przez polecenie BACKUP DATABASE. Wystarczy, że administrator określi archiwum i serwer, na który ma przywrócić dane, i wciśnie jeden przycisk. Ale w bardziej złożonych scenariuszach będziesz musiał użyć RESTORE.

Tworzenie kopii zapasowej i przywracanie DBMS ma swoje własne różnice, które należy wziąć pod uwagę, zwłaszcza podczas przenoszenia archiwum na inny serwer. Na przykład przeanalizujmy niektóre niuanse MS SQL Server. Aby zarchiwizować przy użyciu języka Transact-SQL, użyj polecenia BACKUP DATABASE (istnieje również polecenie delta DIFFERENTIAL) oraz dziennika transakcji BACKUP LOG.
Jeśli kopia zapasowa jest wdrażana na innym serwerze, należy upewnić się, że obecne są te same dyski logiczne. Alternatywnie można ręcznie ustawić poprawne ścieżki do plików bazy danych za pomocą opcji WITH MOVE komendy RESTORE DATABASE.
Prostą sytuacją jest tworzenie kopii zapasowych i przenoszenie baz danych do innych wersji SQL Server. Ta operacja jest obsługiwana, ale w przypadku SQL Server zadziała, jeśli wersja serwera, na którym wdrożona jest kopia, jest taka sama lub nowsza niż ta, na której została utworzona. I jest ograniczenie: nie więcej niż dwie wersje nowsze. Po przywróceniu baza danych będzie w trybie zgodności z wersją, z której dokonano przejścia, czyli nowe funkcje nie będą dostępne. Można to łatwo naprawić, zmieniając COMPATIBILITY_LEVEL. Czy można to zrobić z Pomoc GUI lub SQL.
ALTER DATABASE MyDB SET COMPATIBILITY_LEVEL = 110;
Możesz określić, w której wersji została utworzona kopia, patrząc na nagłówek pliku archiwum. Aby nie eksperymentować, po przejściu na Nowa wersja SQL Server powinien uruchomić bezpłatne narzędzie Microsoft Upgrade Advisor.
Licencja: komercyjne, istnieje darmowa wersja
Obsługiwany DBMS: Oracle 9-11, XE, MySQL, MariaDB, PostgreSQL i MS SQL Server
Kiedy musisz zarządzać kilkoma typami DBMS, kombinacje są nieodzowne. Wybór jest duży. Na przykład Iperius to lekki, bardzo łatwy w użyciu, ale potężny program do tworzenia kopii zapasowych plików, który ma możliwość tworzenia kopii zapasowych baz danych na gorąco bez przerywania lub blokowania. Zapewnia pełną lub przyrostową kopię zapasową. Może tworzyć pełne obrazy dysków w celu automatycznej ponownej instalacji całego systemu. Obsługuje tworzenie kopii zapasowych na NAS, urządzenia USB, streamer, FTP/FTPS, Dysk Google, Dropbox i SkyDrive. Obsługuje kompresję ZIP bez limitu rozmiaru pliku i szyfrowanie AES256, uruchamiając zewnętrzne skrypty i programy. Zawiera bardzo funkcjonalny harmonogram zadań, możliwe jest wykonywanie kilku zadań równolegle lub sekwencyjnie, wynik wysyłany jest na e-mail. Obsługiwane są liczne filtry, zmienne do personalizacji ścieżek i ustawień.

Możliwość przesyłania FTP ułatwia aktualizację informacji na wielu stronach internetowych. Otwórz pliki są archiwizowane przy użyciu technologii VSS (Volume Shadow Copy), która pozwala na wykonanie gorącej kopii zapasowej nie tylko plików DBMS, ale także innych aplikacji. W przypadku Oracle używane jest również narzędzie do tworzenia kopii zapasowych i odzyskiwania danych RMAN (Recovery Manager). Aby nie przeciążać kanału, istnieje możliwość regulacji przepustowości. Zarządzanie kopiami zapasowymi i przywracaniem odbywa się za pomocą konsoli lokalnej i internetowej. Wszystkie funkcje są na widoku, więc aby skonfigurować zadanie, potrzebujesz jedynie zrozumienia procesu, nie musisz nawet zaglądać do dokumentacji. Wystarczy postępować zgodnie z instrukcjami kreatora. Możesz także zwrócić uwagę na menedżera konta, co jest bardzo wygodne w przypadku dużej liczby systemów.
Podstawowe funkcje są oferowane bezpłatnie, ale możliwość redundancji bazy danych jest zawarta tylko w wersjach Advanced DB i Full. Obsługuje instalację od XP do serwer Windowsa 2012.
Licencja: Reklama
Obsługiwany DBMS: Oracle, MySQL, IBM DB2 (7–9.5) i MS SQL Server
Jednym z najpotężniejszych systemów zarządzania relacyjnymi bazami danych jest IBM DB2, który ma unikalne cechy skalowalności i obsługuje wiele platform. Jest dostarczany w kilku edycjach, które są zbudowane na tej samej podstawie i różnią się funkcjonalnie. Architektura bazy danych DB2 umożliwia zarządzanie prawie wszystkimi typami danych: dokumentami, plikami XML, plikami multimedialnymi i tak dalej. Szczególnie popularny jest darmowy DB2 Express-C. Kopia zapasowa jest bardzo prosta:
przykładowa kopia zapasowa bazy danych db2
Lub migawkę przy użyciu funkcji Advanced Copy Services (ACS):
przykładowa kopia zapasowa bazy danych db2 użyj migawki
Musimy jednak pamiętać, że w przypadku snapshotów nie możemy przywrócić (db2 recovery db) poszczególnych tabel. Istnieją możliwości automatycznego tworzenia kopii zapasowych i wiele więcej. Produkty są dobrze udokumentowane, chociaż instrukcje obsługi są rzadkością w rosyjskojęzycznym Internecie. Ponadto nie wszystkie specjalne rozwiązania mogą znaleźć wsparcie dla DB2.
Na przykład, Poręczna kopia zapasowa umożliwia tworzenie kopii zapasowych kilku typów serwerów baz danych i zapisywanie plików na prawie każdym nośniku ( Dysk twardy, CD/DVD, chmura i pamięć sieciowa, FTP/S, WebDAV i inne). Możliwe jest tworzenie kopii zapasowych baz danych przez ODBC (tylko tabele). Jest to jedno z nielicznych rozwiązań obsługujących DB2 i opatrzone logo „Ready for IBM DB2 Data Server Software”. Cała procedura odbywa się za pomocą konwencjonalnego kreatora, w którym wystarczy wybrać żądany element i utworzyć zadanie. Sam proces konfiguracji jest tak prosty, że poradzi sobie z nim nawet początkujący. Możesz utworzyć wiele zadań, które będą uruchamiane zgodnie z harmonogramem. Wynik jest rejestrowany i wysyłany e-mailem. Nie jest konieczne zatrzymywanie usługi podczas wykonywania zadania. Archiwum jest automatycznie kompresowane i szyfrowane, co gwarantuje jego bezpieczeństwo.
Pracę z DB2 wspierają dwie wersje Handy Backup - Office Expert (lokalna) i Server Network (sieciowa). Działa na komputerach z systemem Win8/7/Vista/XP lub 2012/2008/2003. Sam proces wdrażania nie jest trudny dla żadnego administratora.
Nadal rozmawiamy o tworzeniu kopii zapasowych i dzisiaj się tego nauczymy stworzyć archiwum bazy Microsoftu Serwer SQL 2008. Rozważymy wszystko jak zwykle z przykładami, używając zarówno interfejsu graficznego, jak i zapytania SQL, a także skonfigurujemy automatyczne tworzenie kopii zapasowej przy użyciu pliku wsadowego.
Nie wrócimy już do kwestii znaczenia backupu baz danych, skoro już nie raz poruszaliśmy ten temat, np. w materiałach:
A w ostatnim artykule powiedziałem, że rozważymy możliwość stworzenia archiwum na DBMS MS SQL Server 2008, więc teraz właśnie to zrobimy.
A skoro teorii było już sporo, to od razu przejdźmy do praktyki, czyli tworzenia bazy zapasowej.
Notatka! Jak widać z tytułu artykułu, wykonamy archiwum na Microsoft SQL 2008 DBMS za pomocą Management Studio. Serwer jest zlokalizowany lokalnie. System operacyjny Windows 7.
Zdecydujmy, że zrobimy archiwum testowej bazy danych o nazwie „test”. Od początku przez GUI, a w trakcie tego napiszemy skrypt, aby w przyszłości móc go po prostu uruchomić i nie rozpraszać się wprowadzaniem wszelkiego rodzaju parametrów.
Otwórz Management Studio, rozwiń « Baza danych» , wybierz żądaną podstawę, kliknij kliknij prawym przyciskiem myszy najedź na nią myszką, wybierz Zadania->Kopia zapasowa

Zobaczysz okno " Kopia zapasowa bazy danych”, gdzie można ustawić parametry archiwizacji. Podałem tylko nazwę Zestaw zapasowy", a także zmieniłem nazwę archiwum i ścieżkę, ponieważ domyślnie zostanie utworzone w folderze Program Files, na przykład miałem domyślną ścieżkę
C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\Backup\
Na przykład zmieniłem go na C:\temp\ i nazwałem archiwum test_arh.bak

Również jeśli przejdziesz do zakładki « Opcje», następnie możesz ustawić ustawienie nadpisywania wszystkich zestawów danych, teraz wyjaśnię, co to jest. Jeśli zostawisz wszystko tak, jak jest, tj. dodać do istniejącego zestawu danych, to będziesz miał jeden plik kopii zapasowej, ale z kilkoma instancjami zestawów danych, tj. podczas przywracania po prostu wybierasz potrzebny zestaw. A jeśli umieścisz „ Zastąp wszystkie istniejące zestawy kopii zapasowych”, wtedy zestaw będzie zawsze taki sam, wtedy w takim przypadku będziesz musiał utworzyć archiwa (powiedzmy codzienne) o różnych nazwach. Ustawiłem na nadpisywanie, bo powiedzmy w przyszłości planuję tworzyć archiwa na każdy dzień z datą w nazwie tych archiwów, aby w razie potrzeby szybko skopiować potrzebną mi kopię zapasową na określoną datę w dowolne miejsce .

A tak przy okazji, w tym momencie, po wprowadzeniu wszystkich parametrów, można stworzyć skrypt, aby go nagrać i wykorzystać później. Aby to zrobić, po prostu kliknij na górę Scenariusz».
W wyniku tej akcji otworzysz okno zapytania, w którym pojawi się kod dla tego skryptu. Wrócimy do tego trochę później, ale na razie kliknij „OK” i po zakończeniu operacji zobaczysz okno, w którym zostanie wskazany wynik tworzenia kopii zapasowej, jeśli wszystko jest w porządku, pojawi się następujący komunikat pojawić się

Jeśli zrobiłeś wszystko jak powyżej te. kliknąłem „Skrypt”), to otworzyłeś okno zapytania, które faktycznie zawiera samo żądanie utworzenia archiwum, ale zrobimy to trochę ponownie, ponieważ powiedziałem, że planujemy uruchamiać je codziennie, aby nazwa była odpowiednia, napiszemy to Instrukcja SQL.
DECLARE @path AS VARCHAR(200) SET @path = N"C:\temp\test_arh_" + CONVERT(varchar(10), getdate(), 104) + ".bak" KOPIA ZAPASOWA BAZY DANYCH NA DYSEK = @path WITH NOFORMAT, INIT, NAZWA = N"Test bazy danych", SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO
A teraz, jeśli go uruchomimy, utworzymy kopię zapasową bazy danych o nazwie test_arh_ Bieżąca data.bak
Do tych celów MS SQL 2008 ma specjalna okazja zatytułowany " Plany serwisowe”, gdzie można po prostu ustawić harmonogram tworzenia kopii zapasowej bazy danych, ale sugeruję użycie do tych celów pliku nietoperza, aby ustawić go w harmonogramie i uruchamiać codziennie i tworzyć kopię zapasową bazy danych.
Aby to zrobić, skopiuj Instrukcja SQL, który sprawdziliśmy powyżej, i wklej go do notatnika ( Polecam Notepad++), a następnie zapisz z rozszerzeniem .sql te. ten skrypt zostanie wykonany na MS Sql 2008. Następnie będziemy musieli napisać plik wsadowy, aby połączył się z serwerem SQL i wykonał nasz skrypt. Napisz też w notatniku:
SET cur_date=%date:~6,4%%date:~3,2%%date:~0,2% osql -S localhost -i C:\temp\test.sql -o C:\temp\%cur_date %_log_sql.log -E
gdzie utworzyłem zmienną cur_date do przechowywania w niej bieżącej daty, a następnie łączę się z nią lokalny serwer, za pośrednictwem narzędzia osql, który używa ODBC i wykonuje nasz skrypt ( Nazwałem to test.sql), a także napisz dziennik, gdzie i po prostu potrzebowaliśmy naszej zmiennej, to wszystko, zapisz z rozszerzeniem .nietoperz, tworzymy zadanie w harmonogramie i możemy powiedzieć, że zapominamy o procesie archiwizacji bazy, no cóż, tylko okresowo sprawdzamy, czy archiwum zostało utworzone, czy nie.
Dla podstaw to wystarczy, teraz już wiesz, jak tworzyć kopie zapasowe baz danych na serwerze SQL 2008, w następnym artykule przyjrzymy się, jak przywrócić bazę danych na MS SQL Server 2008. Tymczasem to wszystko ! Powodzenia!
A także: kopia zapasowa SQL, kopia zapasowa 1C.
Serwer 1C zawiera dane w bazie danych, która znajduje się na serwerze SQL. Dzisiaj rozważamy MS SQL 2005/2008.
Aby dane nie zostały utracone w przypadku spalenia dysku serwera lub innych sytuacji siły wyższej, konieczne jest tworzenie kopii zapasowych od samego początku.
Oczywiście nikt nie chce codziennie robić długopisów Kopia zapasowa bazy danych SQL 1C. Są do tego automatyczne narzędzia. Poznajmy ich.
Konfigurowanie BackupSQL
Konfigurowanie kopii zapasowej SQL dla bazy danych 1C nie różni się od konfigurowania kopii zapasowej dla dowolnej innej bazy danych.
Aby skonfigurować, uruchom MS SQL Management Studio. Ten program należy do grupy programów MS SQL.
Dodanie zadania tworzenia kopii zapasowej bazy danych 1C SQL
Zadania automatycznego tworzenia kopii zapasowych baz SQL znajdują się w gałęzi Zarządzanie / Plany utrzymania.

Aby dodać nowe zadanie tworzenia kopii zapasowej, kliknij prawym przyciskiem myszy grupę Plany konserwacji i wybierz Nowy plan konserwacji.

Wprowadź nazwę zadania. Imię ma znaczenie tylko dla ciebie. Na wszelki wypadek lepiej jest używać angielskich znaków.
Konfigurowanie zadania tworzenia kopii zapasowej bazy danych 1C SQL
Otworzy się Edytor zadań. Należy pamiętać, że zadania mogą wykonywać różne operacje na bazie danych, a nie tylko kopie zapasowe.
Lista opcji operacji jest wyświetlana w lewym dolnym rogu. Wybierz Zadanie tworzenia kopii zapasowej bazy danych, klikając dwukrotnie lub po prostu przeciągając w prawo.

Zwróć uwagę na strzałkę. Możesz przeciągnąć i upuścić kilka różnych lub identycznych operacji i połączyć je strzałkami. Wtedy kilka zadań zostanie wykonanych jednocześnie w określonej przez Ciebie kolejności.

W oknie ustawień wybierz wymagane bazy danych SQL 1C (możesz mieć kilka lub jedną na raz).

Wybierz lokalizację, w której chcesz zapisać kopię zapasową bazy danych SQL 1C. Musisz wybrać fizycznie inny dysk twardy. Pod względem organizacyjnym możesz zaznaczyć pole „Utwórz podfoldery”.

Teraz skonfigurujmy harmonogram tworzenia kopii zapasowych. Domyślny harmonogram tworzenia kopii zapasowych został dodany sam. Możesz jednak dodać wiele harmonogramów (na przykład jeden dzienny, jeden tygodniowy itd.). Kliknij przycisk ustawień harmonogramu tworzenia kopii zapasowych.

Zrzut ekranu pokazuje przykład codziennej bazy danych Backup SQL 1C o 3 rano.

Aby harmonogram tworzenia kopii zapasowych na liście był ładny i zrozumiały, możesz go zmienić.

Zapisywanie zadania tworzenia kopii zapasowej bazy danych 1C SQL
Kliknij wypal. Zadanie pojawi się po lewej stronie listy.
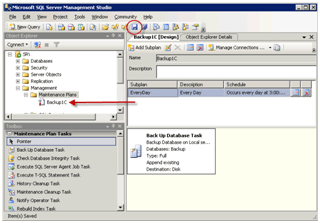
To jest ważne! Sprawdź, czy zadanie Utwórz kopię zapasową bazy danych SQL zostało utworzone poprawnie. Aby to zrobić, kliknij prawym przyciskiem myszy zadanie i wybierz polecenie Wykonaj.
W rezultacie plik kopii zapasowej powinien pojawić się w określonej ścieżce. Jeśli coś jest nie tak, usuń zadanie (Del) i zacznij od początku.
Rozważmy niepożądaną sytuację. Mianowicie: z jakiegoś powodu baza danych zawiodła. Co my mamy? Kopia pełna, kopia różnicowa na wczoraj, ale są też dane na dziś, czy naprawdę trzeba było robić kopię różnicową co godzinę? - NIE! Jeść Dziennik transakcji.
Dziennik transakcji to dziennik rejestrujący wszystkie transakcje i wszystkie zmiany w bazie danych dokonane przez każdą transakcję. Te. każda akcja z bazą danych jest krok po kroku zapisywana w logu. Każdy rekord jest oznaczany przez DBMS do zakończenia transakcji, zakończonej lub nie. Z jego pomocą można przywrócić stan bazy danych nie tylko po awarii, ale także w przypadku nieprzewidzianych działań z danymi. Cofnij do określonego czasu. Podobnie jak w przypadku bazy danych, należy wykonać kopię zapasową dziennika transakcji, pełną, różnicową, przyrostową. Aby przywrócić część dziennika transakcji po awarii między kopiami zapasowymi, należy wykonać kopię zapasową ostatniej części dziennika, która w rzeczywistości jest punktem końcowym tworzenia kopii zapasowej. Wykonywany po wypadku, jako punkt odliczania.
Aby więc przywrócić bazę danych po awarii, potrzebujemy aktualnej pełnej kopii bazy danych, kopii różnicowej bazy danych oraz kopii dziennika transakcji.
W przypadku samej bazy danych dostępne są 3 modele odzyskiwania — proste, pełne i rejestrowane zbiorczo. Rozważać:
Rozważmy najbardziej odpowiedni łańcuch tworzenia kopii zapasowych: Pełna kopia zapasowa — raz w tygodniu, Różnicowa kopia zapasowa — raz dziennie, Kopia zapasowa dziennika transakcji — raz na godzinę.
Istnieje kilka opcji tworzenia kopii zapasowych:
Rozważ pierwszą opcję jako najbardziej użyteczną. W tym celu używany jest system Windows Server 2008 R2 Enterprise i MS SQL Server 2008 Eng.
Powiedzmy, że mamy bazę danych TECH:
Przejdźmy do narzędzia do tworzenia ofert pracy:

Trzy prawy przycisk myszy i wywołanie Master Job:
Zaznaczamy checkbox „Oddzielne wykonanie każdego zadania”, wykonujemy tylko jedną akcję

Mistrz jest bez turbanu, ale najważniejsze nie jest rozmiar turbanu)) Wybieramy rodzaj pragnienia, w naszym przypadku - pełna rezerwacja:

Mistrz Joba, jak się okazało, jest trochę Żydem, więc ponownie pyta:

"Warto wybrać dodatkowe opcje, młody padawan!":
tutaj wybieramy bazę danych, okres przechowywania kopii zapasowej, adres (taśma lub dysk), ścieżkę zapisu i, co najważniejsze, harmonogram zadań!

„Nie zapomnij o bazie danych przy wyborze swojej. Skoncentruj swoją moc i wybierz bazę danych”:

„Za szybko śpieszysz się z utworzeniem zadania, kliknij w przycisk poniżej o nazwie Harmonogram – Zdefiniuj”.
Sobsno, harmonogram zadań, w którym wybieramy typ (powtórzenie, raz itp.), dzień, godzinę, typ startu:
To wszystko, stworzone. Mistrz Joba jest fajny i zielony. Patrzymy na stan w Planach konserwacji:

Dla paranoików nie bójcie się przyznać przed lustrem, warto zajrzeć w duszę SQL Server Agent - Job Activity Monitor, Job Master pokaże wszystko szczegółowo:

Teraz, jeśli spełnione są podane warunki, powinien utworzyć pełna kopia zapasowa DB. Na tej samej zasadzie tworzona jest kopia różnicowa i kopia zapasowa dziennika transakcji (te pozycje podrzędne znajdują się pod „Pełną kopią zapasową” na liście wyboru zadań).
Skręć uszy z MSSQL, jak chcesz, nie odkręcaj
Następny artykuł obejmuje tworzenie za pomocą Transact-SQL i kilka przykładów.








