Id_user - целочисленные значения, значит будет тип int, ограничим его 10 символами - int (10).
name - строковое значение varchar, ограничим его 20 символами - varchar(20).
email - строковое значение varchar, ограничим его 50 символами - varchar(50).
password - строковое значение varchar, ограничим его 15 символами - varchar(15).
Все значения полей обязательны для заполнения, значит надо добавить тип NOT NULL.
Id_user int (10) NOT NULL
name varchar(20) NOT NULL
email varchar(50) NOT NULL
Первый столбец, как вы помните из концептуальной модели нашей БД, является первичным ключом (т.е. его значения уникальны, и они однозначно идентифицируют запись). Следить за уникальностью самостоятельно можно, но не рационально. Для этого в SQL есть специальный атрибут - AUTO_INCREMENT , который при обращении к таблице на добавление данных высчитывает максимальное значение этого столбца, полученное значение увеличивает на 1 и заносит его в столбец. Таким образом, в этом столбце автоматически генерируется уникальный номер, а следовательно тип NOT NULL излишен. Итак, присвоим атрибут столбцу с первичным ключом:
name varchar(20) NOT NULL
email varchar(50) NOT NULL
password varchar(15) NOT NULL
Теперь надо указать, что поле id_user является первичным ключом. Для этого в SQL используется ключевое слово PRIMARY KEY () , в скобочках указывается имя ключевого поля. Внесем изменения:
Id_user int (10) AUTO_INCREMENT
name varchar(20) NOT NULL
email varchar(50) NOT NULL
password varchar(15) NOT NULL
PRIMARY KEY (id_user)
Итак, таблица готова, и ее окончательный вариант выглядит так:
Create table users (
id_user int (10) AUTO_INCREMENT,
name varchar(20) NOT NULL,
email varchar(50) NOT NULL,
password varchar(15) NOT NULL,
PRIMARY KEY (id_user)
);
Теперь разберемся со второй таблицей - topics (темы). Рассуждая аналогично, имеем следующие поля:
id_author int (10) NOT NULL
PRIMARY KEY (id_topic)
Но в модели нашей БД поле id_author является внешним ключом, т.е. оно может иметь только те значения, которые есть в поле id_user таблицы users. Для того, чтобы указать это в SQL есть ключевое слово FOREIGN KEY () , которое имеет следующий синтаксис:
FOREIGN KEY (имя_столбца_которое_является_внешним_ключом) REFERENCES имя_таблицы_родителя (имя_столбца_родителя);
Укажем, что id_author - внешний ключ:
Id_topic int (10) AUTO_INCREMENT
topic_name varchar(100) NOT NULL
id_author int (10) NOT NULL
PRIMARY KEY (id_topic)
FOREIGN KEY (id_author) REFERENCES users (id_user)
Таблица готова, и ее окончательный вариант выглядит так:
Create table topics (
id_topic int (10) AUTO_INCREMENT,
topic_name varchar(100) NOT NULL,
PRIMARY KEY (id_topic),
FOREIGN KEY (id_author) REFERENCES users (id_user)
);
Осталась последняя таблица - posts (сообщения). Здесь все аналогично, только два внешних ключа:
Create table posts (
id_post int (10) AUTO_INCREMENT,
message text NOT NULL,
id_author int (10) NOT NULL,
id_topic int (10) NOT NULL,
PRIMARY KEY (id_post),
FOREIGN KEY (id_author) REFERENCES users (id_user),
FOREIGN KEY (id_topic) REFERENCES topics (id_topic)
);
Обратите внимание, внешних ключей у таблицы может быть несколько, а первичный ключ в MySQL может быть только один. В первом уроке мы удалили нашу БД forum, пришло время создать ее вновь.
Запускаем сервер MySQL (Пуск - Программы - MySQL - MySQL Server 5.1 - MySQL Command Line Client), вводим пароль, создаем БД forum (create database forum;), выбираем ее для использования (use forum;) и создаем три наших таблицы:
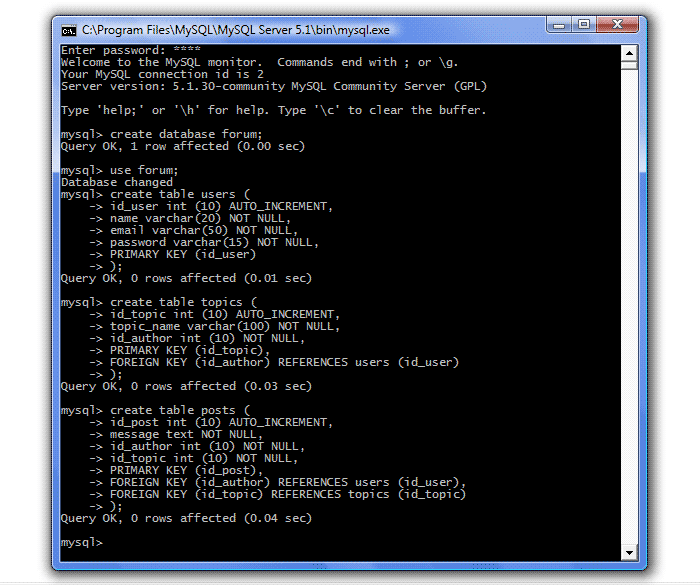
Обратите внимание, одну команду можно писать в несколько строк, используя клавишу Enter (MySQL автоматически подставляет символ новой строки ->), и только после разделителя (точки с запятой) нажатие клавиши Enter приводит к выполнению запроса.
Помните, если вы сделали что-то не так, всегда можно удалить таблицу или всю БД с помощью оператора DROP. Исправлять что-то в командной строке крайне неудобно, поэтому иногда (особенно на начальном этапе) проще писать запросы в каком-нибудь редакторе, например в Блокноте, а затем копировать и вставлять их в черное окошко.
Итак, таблицы созданы, чтобы убедиться в этом вспомним о команде show tables :

И, наконец, посмотрим структуру нашей последней таблицы posts:

Теперь становятся понятны значения всех полей структуры, кроме поля DEFAULT. Это поле значений по умолчанию. Мы могли бы для какого-нибудь столбца (или для всех) указать значение по умолчанию. Например, если бы у нас было поле с названием "Женаты\Замужем" и типом ENUM ("да", "нет"), то было бы разумно сделать одно из значений значением по умолчанию. Синтаксис был бы следующий:
Married enum ("да", "нет") NOT NULL default("да")
Т.е. это ключевое слово пишется через пробел после указания типа данных, а в скобках указывается значение по умолчанию.
Но вернемся к нашим таблицам. Теперь нам необходимо внести данные в наши таблицы. На сайтах, вы обычно вводите информацию в какие-нибудь html-формы, затем сценарий на каком-либо языке (php, java...) извлекает эти данные из формы и заносит их в БД. Делает он это посредством SQL-запроса на внесение данных в базу. Писать сценарии на php мы пока не умеем, а вот отправлять SQL-запросы на внесение данных сейчас научимся.
Для этого используется оператор INSERT
. Синтаксис можно использовать двух видов. Первый вариант используется
для внесения данных во все поля таблицы:
INSERT INTO имя_таблицы VALUES ("значение_первого_столбца","значение_второго_столбца", ..., "значение_последнего_столбца");
INSERT INTO users VALUES ("1","sergey", "[email protected]", "1111");

Второй вариант используется для внесения данных в некоторые поля таблицы:
INSERT INTO имя_таблицы ("имя_столбца", "имя_столбца") VALUES ("значение_первого_столбца","значение_второго_столбца");
INSERT INTO users (name, email, password) VALUES ("valera", "[email protected]", "2222");

Если бы у нас были поля с типом NULL, т.е. необязательные для заполнения, мы бы тоже могли их проигнорировать. А вот если попытаться оставить пустым поле со значением NOT NULL, то сервер выдаст сообщение об ошибке и не выполнит запрос. Кроме того, при внесении данных сервер проверяет связи между таблицами. Поэтому вам не удастся внести в поле, являющееся внешним ключом, значение, отсутствующее в связанной таблице. В этом вы убедитесь, внося данные в оставшиеся две таблицы.
Но прежде внесем информацию еще о нескольких пользователях. Чтобы добавить сразу несколько строк, надо просто перечислять скобки со значениями через запятую:

Теперь внесем данные во вторую таблицу - topics (темы). Все тоже самое, но надо помнить, что значения в поле id_author должны присутствовать в таблице users (пользователи):

Теперь давайте попробуем внести еще одну тему, но с id_author, которого в таблице users нет (т.к. мы внесли в таблицу users только 5 пользователей, то id=6 не существует):

Сервер выдает ошибку и говорит, что не может внести такую строку, т.к. в поле, являющемся внешним ключом, стоит значение, отсутствующее в связанной таблице users.
Теперь внесем несколько строк в таблицу posts (сообщения), помня, что в ней у нас 2 внешних ключа, т.е. id_author и id_topic, которые мы будем вносить должны присутствовать в связанных с ними таблицах:

Итак, у нас есть 3 таблицы, в которых есть данные. Встает вопрос - как посмотреть, какие данные хранятся в таблицах. Этим мы и займемся на следующем уроке.
Работа с базами данных непосредственно связана с изменением таблиц и содержащихся в них данных. Но перед началом проведения действий таблицы необходимо создать. Для автоматизации этого процесса существует специальная - "CREATE TABLE".
Перед тем как разбираться с процессом создания таблиц с помощью команды MS SQL "CREATE TABLE", стоит остановиться на том, что надо знать перед началом использования функции.
Прежде всего, необходимо придумать имя таблице - оно должно быть уникальным, в сравнении с другими, находящимися в базе данных, и следовать нескольким правилам. Имя должно начинаться с буквы (a-z), после чего могут следовать любые буквы, цифры и знак подчеркивания, при этом полученная фраза не должна быть зарезервированным словом. Длина названия таблицы не должна превышать 18 символов.
Определившись с именем, следует разработать структуру: придумать названия столбцам, продумать используемый в них тип данных и какие поля должны быть обязательно заполнены. Здесь же стоит сразу определить поля внешних и первичных ключей, а также возможные ограничения для значений данных.
Остальные нюансы таблицы можно достаточно легко подкорректировать, поэтому на этапе создания таблицы они могут быть продуманы не до конца.
Разработав структуру таблицы, можно переходить к её созданию. Сделать это достаточно просто, воспользовавшись функцией SQL "CREATE TABLE". В ней пользователю требуется указать придуманные ранее имя таблицы и список столбцов, указав для каждого из них тип и имя. Синтаксис функции выглядит следующим образом:
CREATE TABLE table_name
({column_name datatype …| table_constraint}
[,{column_name datatype …| table_constraint}]…)
Аргументы, используемые в конструкции функции, означают следующее:
Также возможно использование ещё двух аргументов функции:
В них пользователь может указать требуемые для работы ограничения или условия заполнения таблицы.
При написании запроса с функцией иногда необходимо установить правила заполнения полей. Для этого необходимо добавить специальные атрибуты функции, определяющие тот или иной набор условий.
Для того чтобы определить, может ли в ячейке находиться пустое значение, после указания имени и типа столбца следует прописать одно из ключевых слов: NULL (могут быть пустые значения) или NOT NULL (поле должно быть заполнено).
При создании таблицы в большинстве случаев требуется унифицировать каждую запись, чтобы избежать наличия двух одинаковых. Для этого чаще всего используют нумерацию строк. И, чтобы не требовать от пользователя знания последнего номера, имеющегося в таблице, в функции "CREATE TABLE" достаточно указать столбец первичного ключа, написав ключевое слово "Primary key" после соответствующего поля. Чаще всего именно по первичному ключу и происходит соединение таблиц между собой.

Для обеспечения сцепки с Primary key используется свойство внешнего ключа "FOREIGN KEY". Указав для столбца данное свойство, можно обеспечить, что в данном поле будет содержаться значение, совпадающее с одним из тех, что находятся в столбце первичного ключа этой же или другой таблицы. Таким образом можно обеспечить соответствие данных.
Чтобы обеспечить проверку на соответствие некоторому заданному набору или определению, следует воспользоваться атрибутом CHECK. Он прописывается последним в списке аргументов функции и в качестве личного параметра имеет некоторое логическое выражение. С его помощью можно ограничить список возможных значений, например, использование в поле таблицы "Пол" только буквы "М" и "Ж".
Помимо представленных, функция имеет ещё множество специфических атрибутов, однако они используются на практике гораздо реже.
Чтобы полноценно понять принцип работы функции, стоит рассмотреть на практике, как работает CREATE TABLE (SQL). Пример, приведенный ниже, создает таблицу, представленную на рисунке:
CREATE TABLE Custom
(ID CHAR(10) NOT NULL Primary key,
Custom_name CHAR(20),
Custom_address CHAR(30),
Custom_city CHAR(20),
Custom_Country CHAR(20),
ArcDate CHAR(20))
Как можно заметить, параметр возможного отсутствия значения в ячейке (NULL) можно опускать, так как он используется по умолчанию.
Если у Вас возникала необходимость сохранить результирующий набор данных, который вернул SQL запрос, то данная статья будет Вам интересна, так как в ней мы рассмотрим инструкцию SELECT INTO , с помощью которой в Microsoft SQL Server можно создать новую таблицу и заполнить ее результатом SQL запроса.
Начнем мы, конечно же, с описания самой инструкции SELECT INTO, а затем перейдем к примерам.
SELECT INTO – инструкция в языке в T-SQL, которая создает новую таблицу и вставляет в нее результирующие строки из SQL запроса. Структура таблицы, т.е. количество и имена столбцов, а также типы данных и свойства допустимости значений NULL, будут на основе столбцов (выражений ), указанных в списке выбора из источника в инструкции SELECT. Обычно инструкция SELECT INTO используется для объединения в одной таблице данных из нескольких таблиц, представлений, включая какие-то расчетные данные.
Для того чтобы использовать инструкцию SELECT INTO требуется разрешение CREATE TABLE в базе данных, в которой будет создана новая таблица.
Инструкция SELECT INTO имеет два аргумента:
Все примеры я буду выполнять в СУБД Microsoft SQL Server 2016 Express .
Для начала давайте создадим две таблицы и заполним их данными, эти таблицы мы и будем объединять в примерах.
CREATE TABLE TestTable( IDENTITY(1,1) NOT NULL, NOT NULL, (100) NOT NULL, NULL) ON GO CREATE TABLE TestTable2( IDENTITY(1,1) NOT NULL, (100) NOT NULL) ON GO INSERT INTO TestTable VALUES (1,"Клавиатура", 100), (1, "Мышь", 50), (2, "Телефон", 300) GO INSERT INTO TestTable2 VALUES ("Комплектующие компьютера"), ("Мобильные устройства") GO SELECT * FROM TestTable SELECT * FROM TestTable2
Давайте представим, что нам необходимо объединить две таблицы и сохранить полученный результат в новую таблицу (например, нам нужно получить товары с названием категории, к которой они относятся ).
Операция SELECT INTO SELECT T1.ProductId, T2.CategoryName, T1.ProductName, T1.Price INTO TestTable3 FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId --Выборка данных из новой таблицы SELECT * FROM TestTable3

В итоге мы создали таблицу с названием TestTable3 и заполнили ее объединёнными данными.
Сейчас давайте, допустим, что нам нужны сгруппированные данные, например, информация о количестве товаров в определенной категории, при этом эти данные нам нужно сохранить во временную таблицу, например, эту информацию мы будем использовать только в SQL инструкции, поэтому нам нет необходимости создавать полноценную таблицу.
Создаем временную таблицу (#TestTable) с помощью инструкции SELECT INTO SELECT T2.CategoryName, COUNT(T1.ProductId) AS CntProduct INTO #TestTable FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId GROUP BY T2.CategoryName --Выборка данных из временной таблицы SELECT * FROM #TestTable

Как видим, у нас получилось создать временную таблицу #TestTable и заполнить ее сгруппированными данными.
Вот мы с Вами и рассмотрели инструкцию SELECT INTO в языке T-SQL, в своей книге «Путь программиста T-SQL » я подробно рассказываю про все конструкции языка T-SQL (рекомендую почитать ), а у меня на этом все, пока!








