Id_user - integer értékek, tehát int lesz a típus, korlátozzuk 10 karakterre - int (10).
A név egy varchar karakterlánc érték, korlátozzuk 20 karakterre - varchar(20).
Az email egy varchar karakterlánc érték, korlátozzuk 50 karakterre - varchar(50).
jelszó - varchar karakterlánc értéke, korlátozzuk 15 karakterre - varchar(15).
Minden mezőérték kötelező, ezért hozzá kell adnia NEM típus NULLA.
id_user int(10) NEM NULL
név varchar(20) NOT NULL
email varchar(50) NOT NULL
Az első oszlop, amint az adatbázisunk fogalmi modelljéből emlékszik, az elsődleges kulcs (azaz értékei egyediek, és egyedileg azonosítanak egy rekordot). Lehet egyedül követni az egyediséget, de nem racionális. Az SQL-ben erre van egy speciális attribútum - AUTO_INCREMENT, amely a táblázathoz való hozzáféréskor az adatok hozzáadásához kiszámolja ennek az oszlopnak a maximális értékét, az így kapott értéket 1-gyel növeli és az oszlopba helyezi. Így ebben az oszlopban automatikusan létrejön egy egyedi szám, ezért a NOT NULL típus redundáns. Tehát rendeljünk egy attribútumot egy elsődleges kulccsal rendelkező oszlophoz:
név varchar(20) NOT NULL
email varchar(50) NOT NULL
jelszó varchar(15) NOT NULL
Most meg kell adnunk, hogy az id_user mező az elsődleges kulcs. Ehhez az SQL használja kulcsszó ELSŐDLEGES KULCS(), a kulcsmező neve zárójelben van feltüntetve. Változtassunk:
id_user int(10) AUTO_INCREMENT
név varchar(20) NOT NULL
email varchar(50) NOT NULL
jelszó varchar(15) NOT NULL
ELSŐDLEGES KULCS (ID_user)
Tehát a táblázat készen áll, és a végleges verziója így néz ki:
Táblázatfelhasználók létrehozása (
id_user int(10) AUTO_INCREMENT,
név varchar(20) NOT NULL,
email varchar(50) NOT NULL,
jelszó varchar(15) NOT NULL,
ELSŐDLEGES KULCS (ID_user)
);
Most foglalkozzunk a második táblázattal - témák (témák). Hasonlóan érvelve a következő mezőkkel rendelkezünk:
id_author int(10) NOT NULL
ELSŐDLEGES KULCS (id_topic)
Ám a mi adatbázismodellünkben az id_author mező egy idegen kulcs, pl. csak olyan értékei lehetnek, amelyek a felhasználók tábla id_user mezőjében vannak. Ennek SQL-ben történő megadásához van egy kulcsszó IDEGEN KULCS(), amelynek szintaxisa a következő:
IDEGEN KULCS (oszlopnév_amely_idegen_kulcs) HIVATKOZÁS szülőtábla_neve (szülő_oszlop_neve);
Adjuk meg, hogy az id_author egy idegen kulcs:
id_topic int(10) AUTO_INCREMENT
téma_neve varchar(100) NOT NULL
id_author int(10) NOT NULL
ELSŐDLEGES KULCS (id_topic)
IDEGEN KULCS (id_author) REFERENCES felhasználó (id_user)
A táblázat készen áll, a végleges változata így néz ki:
Hozzon létre táblázattémákat (
id_topic int(10) AUTO_INCREMENT,
topic_name varchar(100) NOT NULL,
ELSŐDLEGES KULCS(id_topic),
IDEGEN KULCS (id_author) REFERENCES felhasználó (id_user)
);
Marad az utolsó táblázat - hozzászólások (üzenetek). Itt minden hasonló, csak két idegen kulcs:
Hozzon létre táblázat bejegyzéseket (
id_post int(10) AUTO_INCREMENT,
üzenet szövege NOT NULL,
id_author int(10) NOT NULL,
id_topic int(10) NOT NULL,
ELSŐDLEGES KULCS (id_post),
IDEGEN KULCS (id_author) REFERENCIA felhasználók (id_user),
IDEGEN KULCS (id_topic) REFERENCES téma (id_topic)
);
Felhívjuk figyelmét, hogy egy táblának több idegen kulcsa is lehet, és a MySQL-ben csak egy elsődleges kulcs lehet. Az első leckében töröltük a fórum adatbázisunkat, ideje újra létrehozni.
Elindítjuk MySQL szerver(Start - Programok - MySQL - Saját SQL szerver 5.1 - MySQL Command Line Client), adjon meg egy jelszót, hozzon létre egy fórum adatbázist (hozzon létre adatbázis fórumot;), válassza ki a használatra (használjon fórumot;), és hozza létre a három táblázatunkat:
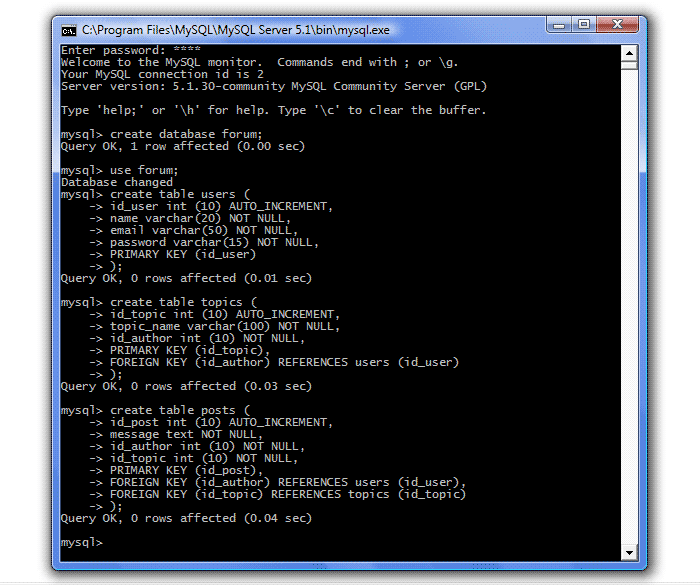
Kérjük, vegye figyelembe, hogy egy parancs több sorban írható az Enter billentyűvel (a MySQL automatikusan behelyettesíti az újsor karaktert ->), és csak az elválasztó (pontosvessző) után az Enter billentyű lenyomása hajtja végre a lekérdezést.
Ne feledje, ha valamit rosszul csinál, a DROP utasítással bármikor eldobhat egy táblát vagy a teljes adatbázist. javítani valamit parancs sor rendkívül kényelmetlen, ezért néha (különösen a kezdeti szakaszban) egyszerűbb lekérdezéseket írni néhány szerkesztőben, például a Jegyzettömbben, majd másolni és beilleszteni a fekete dobozba.
Szóval, a táblázatok azért készültek, hogy ez biztos legyen, emlékezzünk a csapatra táblázatokat mutasson:

És végül nézzük meg legutóbbi bejegyzéseink táblázatának felépítését:

Most a DEFAULT mező kivételével a struktúra összes mezőjének jelentése világossá válik. Ez az alapértelmezett értékmező. Megadhatunk alapértelmezett értéket egyes oszlopokhoz (vagy az összeshez). Például, ha van egy "Házas\Házas" nevű és ENUM típusú mezőnk ("igen", "nem"), akkor érdemes az egyik értéket alapértelmezett értékké tenni. A szintaxis a következő lenne:
Házas enum ("igen", "nem") NOT NULL alapértelmezett ("igen")
Azok. ez a kulcsszó szóközzel van írva az adattípus után, és az alapértelmezett érték zárójelben van feltüntetve.
De térjünk vissza az asztalainkhoz. Most adatokat kell beírnunk a tábláinkba. Weboldalakon általában valamilyen html űrlapba írunk be információkat, majd egy script valamilyen nyelven (php, java...) kivonja ezeket az adatokat az űrlapból és beviszi az adatbázisba. Ezt egy SQL lekérdezéssel teszi, hogy adatokat vigyen be az adatbázisba. Még nem tudjuk, hogyan kell php-ban szkripteket írni, de most megtanuljuk, hogyan kell SQL lekérdezéseket küldeni az adatok beviteléhez.
Ehhez az operátort használják BESZÁLLÍTÁS. A szintaxis kétféleképpen használható. Az első opció az adatok bevitelére szolgál a táblázat összes mezőjébe:
INSERT INTO táblanév ÉRTÉKEK ("első_oszlop_értéke", "második_oszlop_értéke", ..., "utolsó_oszlop_értéke");
INSERT INTO felhasználói ÉRTÉKEK ("1","szergej", " [e-mail védett]", "1111");

A második lehetőség az adatok bevitelére szolgál a táblázat egyes mezőibe:
INSERT INTO táblázat_neve ("oszlopnév", "oszlop_neve") ÉRTÉKEK ("első_oszlop_értéke", "második_oszlop_értéke");
INSERT INTO felhasználók (név, e-mail, jelszó) ÉRTÉKEK ("valera", " [e-mail védett]", "2222");

Ha NULL típusú mezőink lennének, pl. opcionális, figyelmen kívül is hagyhatjuk őket. De ha megpróbálja üresen hagyni a NOT NULL értékű mezőt, a szerver hibaüzenetet ad ki, és nem teljesíti a kérést. Emellett az adatok bevitelekor a szerver ellenőrzi a táblák közötti kapcsolatokat. Ezért nem tölthet fel olyan mezőt, amely idegen kulcs, olyan értékkel, amely nem szerepel a kapcsolódó táblában. Ezt a fennmaradó két táblázatban szereplő adatok megadásával ellenőrizheti.
Először azonban adjunk hozzá néhány további felhasználóról szóló információt. Ha egyszerre több sort szeretne hozzáadni, csak fel kell sorolnia a zárójeleket vesszővel elválasztott értékekkel:

Most adjunk hozzá adatokat a második táblázathoz - témák. Minden ugyanaz, de emlékeznünk kell arra, hogy az id_author mező értékeinek jelen kell lenniük a felhasználók táblájában (felhasználók):

Most próbáljunk meg felvenni egy másik témát, de egy id_author azonosítóval, amely nem szerepel a felhasználók táblájában (mivel csak 5 felhasználót vettünk fel a felhasználók táblájába, az id=6 nem létezik):

A szerver hibát ad, és azt mondja, hogy nem tud ilyen sort beírni, mert az idegen kulcs mező értéke nem szerepel a kapcsolódó felhasználók táblájában.
Most adjunk hozzá néhány sort a hozzászólások táblázatához (üzenetek), ne feledjük, hogy van benne 2 idegen kulcsunk, pl. Az általunk beírt id_author és id_topic szerepelnie kell a hozzájuk tartozó táblázatokban:

Tehát van 3 táblánk, amelyekben adatok vannak. Felmerül a kérdés - hogyan lehet megnézni, hogy milyen adatok vannak a táblákban tárolva. Ezt fogjuk tenni a következő leckében.
Az adatbázisokkal való munka közvetlenül kapcsolódik a táblák és a bennük lévő adatok megváltoztatásához. A műveletek megkezdése előtt azonban létre kell hozni a táblázatot. Ennek a folyamatnak az automatizálására van egy speciális - "TÁBLÁZAT LÉTREHOZÁSA".
Mielőtt az MS SQL "CREATE TABLE" parancsával táblák létrehozásának folyamatával foglalkoznánk, érdemes elidőzni azon, hogy mit kell tudni a függvény használata előtt.
Mindenekelőtt meg kell adnia a tábla nevét – egyedinek kell lennie az adatbázisban szereplő többihez képest, és be kell tartania néhány szabályt. A névnek egy betűvel (a-z) kell kezdődnie, amelyet bármilyen betű, szám és aláhúzás követ, és a kapott kifejezés nem lehet fenntartott szó. A táblázat nevének hossza nem haladhatja meg a 18 karaktert.
A név elhatározása után alakítsunk ki egy struktúrát: adjunk nevet az oszlopoknak, gondoljuk át, milyen adattípust használunk azokban, és mely mezőket kell kitölteni. Érdemes azonnal meghatározni az idegen és elsődleges kulcsok mezőit, valamint az adatértékekre vonatkozó esetleges korlátozásokat is.
A táblázat fennmaradó árnyalatai könnyen korrigálhatók, így a táblázat elkészítésének szakaszában előfordulhat, hogy nem teljesen átgondoltak.
A táblázat szerkezetének kidolgozása után folytathatja a létrehozását. Ez elég könnyen megtehető a "CREATE TABLE" SQL funkcióval. Ebben a felhasználónak meg kell adnia a korábban kitalált táblanevet és az oszlopok listáját, megjelölve mindegyik típusát és nevét. A függvény szintaxisa a következő:
CREATE TABLE table_name
((oszlop_neve adattípus …| táblázat_megszorítás)
[,(oszlopnév adattípus …| táblázat_megszorítás)]…)
A függvény felépítésében használt argumentumok a következőket jelentik:
Két további függvényargumentum is használható:
Ezekben a felhasználó megadhatja a munkához szükséges megszorításokat vagy a táblázat kitöltésének feltételeit.
Függvényes lekérdezés írásakor néha szükséges a mezők kitöltési szabályainak megállapítása. Ehhez speciális függvényattribútumokat kell hozzáadnia, amelyek egy adott feltételkészletet határoznak meg.
Annak megállapításához, hogy egy cellában lehet-e üres érték, az oszlop nevének és típusának megadása után a kulcsszavak egyikét kell beírni: NULL (lehet üres értékek) vagy NEM NULL (a mezőt ki kell tölteni).
Táblázat létrehozásakor a legtöbb esetben egyesíteni kell az egyes rekordokat, hogy ne legyen két egyforma. Ehhez leggyakrabban sorszámozást használnak. És annak érdekében, hogy a felhasználónak ne kelljen tudnia a táblázatban elérhető utolsó számot, elegendő az elsődleges kulcs oszlopát megadni a "TÁBLÁZAT LÉTREHOZÁSA" funkcióban az "Elsődleges kulcs" kulcsszó beírásával a megfelelő mező után. Leggyakrabban az elsődleges kulcs segítségével kapcsolják össze a táblákat.

A „FOREIGN KEY” idegen kulcs tulajdonság az elsődleges kulccsal való kapcsolat biztosítására szolgál. Ha megadja ezt a tulajdonságot egy oszlophoz, akkor biztosíthatja, hogy ez a mező olyan értéket tartalmazzon, amely megegyezik az ugyanazon vagy egy másik tábla elsődleges kulcs oszlopában található értékekkel. Így biztosítható az adatok konzisztenciája.
Egy adott halmazhoz vagy definícióhoz való ellenőrzéshez használja a CHECK attribútumot. Utoljára íródik a függvényargumentumok listájában, és van némi értéke privát paraméterként. logikai kifejezés. Segítségével korlátozhatja a lehetséges értékek listáját, például a táblázat "Nem" mezőjében csak az "M" és "F" betűket használja.
A bemutatottakon kívül a függvénynek még sok specifikus attribútuma van, de a gyakorlatban sokkal ritkábban használatosak.
A függvény működésének teljes megértéséhez érdemes a gyakorlatban átgondolni a CREATE TABLE (SQL) működését. Az alábbi példa az ábrán látható táblázatot hozza létre:
TÁBLÁZAT LÉTREHOZÁSA Egyéni
(ID CHAR(10) NOT NULL Elsődleges kulcs,
Egyéni_név CHAR(20),
Egyéni_címCHAR(30),
Egyéni_város CHAR(20),
Custom_CountryCHAR(20),
ArcDateCHAR(20))
Amint látható, a cellában található érték esetleges hiányának paramétere (NULL) elhagyható, mivel alapértelmezés szerint ez használatos.
Ha el kellett mentenie az SQL lekérdezés által visszaadott adatkészletet, akkor ez a cikk érdekes lesz, mert figyelembe vesszük SELECT INTO utasítás, mellyel új táblát hozhatunk létre a Microsoft SQL Serverben és kitölthetjük az eredménnyel SQL lekérdezés.
Kezdjük természetesen magának a SELECT INTO utasításnak a leírásával, majd továbblépünk a példákra.
VÁLASZTÁS BE- egy T-SQL nyelvű utasítás, amely egy új táblát hoz létre, és az SQL lekérdezésből kapott sorokat beszúrja abba. Táblázat szerkezet, i.e. az oszlopok száma és neve, valamint az adattípusok és a érvényteleníthetőségi tulajdonságok oszlop alapúak lesznek ( kifejezéseket) megadva a SELECT utasítás forráskiválasztási listájában. Általában a SELECT INTO utasítást arra használják, hogy több tábla, nézet adatait egy táblázatban egyesítsék, beleértve néhány számított adatot is.
A SELECT INTO utasításhoz CREATE TABLE engedély szükséges az adatbázishoz, amelyben az új tábla létrejön.
A SELECT INTO utasításnak két argumentuma van:
Az összes példát a Microsoft SQL Server 2016 Express DBMS-ben fogom futtatni.
Kezdésként hozzunk létre két táblát és töltsük fel adatokkal, ezeket a táblázatokat kombináljuk a példákban.
TÁBLÁZAT LÉTREHOZÁSA TesztTable( IDENTITY(1,1) NOT NULL, NOT NULL, (100) NOT NULL, NULL) ON GO CREATE TABLE TestTable2( IDENTITY(1,1) NOT NULL, (100) NOT NULL) ON GO INSERT INTO TestTable ÉRTÉKEK (1,"Billentyűzet", 100), (1, "Egér", 50), (2, "Telefon", 300) GO BESZÚRÁS A 2. teszttáblázatba ÉRTÉKEK (" Számítógép alkatrészek"), ("Mobil eszközök") GO SELECT * FROM TestTable SELECT * FROM TestTable2
Képzeljük el, hogy két táblát össze kell vonnunk, és az eredményt egy új táblában kell tárolnunk ( például olyan termékeket kell beszereznünk, amelyek kategóriájába tartoznak).
Művelet SELECT INTO SELECT T1.ProductId, T2.CategoryName, T1.ProductName, T1.Price INTO TestTable3 FROM TestTable T1 LEFT JOIN TestTable2 T2 ON T1.CategoryId = T2.CategoryId --Adatok kiválasztása egy új táblából * FROMTSELECT3

Ennek eredményeként létrehoztunk egy TestTable3 táblát, és feltöltöttük az egyesített adatokkal.
Most tegyük fel, hogy szükségünk van csoportosított adatokra, például egy bizonyos kategóriába tartozó termékek számára vonatkozó információkra, míg ezeket az adatokat egy ideiglenes táblában kell tárolnunk, például ezeket az információkat csak SQL utasításokban fogjuk használni, így nem kell teljes értékű táblázatot létrehoznia.
Hozzon létre egy ideiglenes táblát (#TestTable) a SELECT INTO SELECT T2.CategoryName, COUNT(T1.ProductId) AS CntProduct INTO használatával adatok egy ideiglenes táblából SELECT * FROM #TestTable

Amint látja, sikerült létrehoznunk egy ideiglenes #TestTable táblát és feltölteni csoportosított adatokkal.
Tehát Ön és én megvizsgáltuk a SELECT INTO utasítást a T-SQL nyelven, a „T-SQL programozó útja” című könyvemben részletesen beszélek az összes konstrukcióról. T-SQL (Olvasásra ajánlom), és egyelőre ennyi!








