Gli amministratori di database si dividono in coloro che eseguono i backup e coloro che eseguiranno i backup.
Questo articolo descrive il backup più comune di IB 1C utilizzando gli strumenti MS server SQL 2008 R2, spiega perché si dovrebbe fare così e non altrimenti, e sfata diversi miti. L'articolo ha molti collegamenti alla documentazione di MS SQL, questo articolo è più una panoramica dei meccanismi di backup che una guida completa. Ma per coloro che affrontano questo compito per la prima volta, vengono fornite istruzioni semplici e passo passo che si applicano a situazioni semplici. L'articolo non è destinato ai guru dell'amministrazione, i guru sanno già tutto questo, ma si presume che il lettore sia in grado di installare MS SQL Server da solo e costringere questo miracolo della tecnologia ostile a creare un database nelle sue viscere, che a sua volta è in grado di forzare la memorizzazione dei dati 1C.
Considero il comando TSQL BACKUP DATABASE (e suo fratello BACKUP LOG) essenzialmente l'unico strumento di backup per database 1C che utilizzano MS SQL Server come DBMS. Perché? Diamo un'occhiata a quali metodi abbiamo generalmente:
| Come | Bene | Male | Totale |
| Carica su dt | Formato molto compatto. | Ci vuole molto tempo per formarsi, richiede un accesso esclusivo, non salva alcuni dati insignificanti (come le impostazioni utente nelle versioni precedenti), ci vuole molto tempo per la distribuzione. | Questo non è tanto un metodo di backup, ma un modo per trasferire i dati da un ambiente all'altro. Ideale per canali stretti. |
| Copia di file mdf e ldf | Un modo molto chiaro per gli amministratori alle prime armi. | Richiede il rilascio dei file di database dal blocco, e questo è possibile se il database è disabilitato (comando take offline menù contestuale), disconnesso (distacco) o semplicemente arrestato il server. Ovviamente, gli utenti non potranno lavorare in questo momento. | Ha senso applicare questo metodo se e solo se si è già verificato un errore, in modo che durante il tentativo di ripristino sia almeno possibile tornare all'opzione da cui è iniziato il ripristino. |
| Backup tramite sistema operativo o hypervisor | Un modo conveniente per gli ambienti di sviluppo e test. | Non sempre amichevole con l'integrità dei dati. modo ad alta intensità di risorse. | Può avere un'applicazione limitata per lo sviluppo. Non ha alcun significato pratico nell'ambiente alimentare. |
| Backup utilizzando MS SQL | Non richiede tempi di inattività. Ti consente di ripristinare uno stato coerente in un momento arbitrario, se te ne occupi in anticipo. Perfettamente automatizzato. Risparmia tempo e altre risorse. | Non molto compatto. Non tutti sanno come utilizzare questo metodo nella misura necessaria. | Per gli ambienti di produzione: lo strumento principale. |
Le principali difficoltà quando si utilizza il backup utilizzando gli strumenti MS SQL integrati sorgono a causa di un elementare fraintendimento dei principi di funzionamento. Ciò è in parte spiegato da una grande pigrizia, in parte dalla mancanza di una spiegazione semplice e comprensibile a livello di "ricette già pronte" (hmm, diciamo, non l'ho visto), e la situazione è addirittura aggravata dal mitologico consigli di "under-guru" sui forum. Non so cosa fare con la pigrizia, ma cercherò di spiegare le basi del backup.
Molto tempo fa, in una galassia lontana, esisteva un prodotto del pensiero ingegneristico e contabile come 1C: Enterprise 7.7. Apparentemente a causa del fatto che le prime versioni di 1C:Enterprise sono state sviluppate per utilizzare il popolare formato di file dbf, la sua versione SQL non memorizzava informazioni sufficienti nel database per considerare completo il backup di MS SQL, e anche con ogni modifica nella struttura, condizioni operative del modello di ripristino completo, quindi è stato necessario ricorrere a diversi accorgimenti per far sì che il sistema di backup svolgesse la sua funzione principale. Ma, da quando è uscita la versione 8, i DBA sono finalmente riusciti a rilassarsi. Gli strumenti di backup regolari consentono di creare un sistema completo e completo di backup. Solo il registro di registrazione e alcune piccole cose come l'impostazione della posizione dei moduli (nelle versioni precedenti) non sono inclusi nel backup, ma questa perdita di questi dati non pregiudica la funzionalità del sistema, sebbene sia sicuramente corretto e utile per effettuare copie di backup del registro di registrazione.
Perché abbiamo bisogno di un backup? Hm. A prima vista, questa è una domanda strana. Ebbene, probabilmente, in primo luogo, poter distribuire una copia del sistema e, in secondo luogo, ripristinare il sistema in caso di guasto? Sono d'accordo sul primo, ma il secondo appuntamento è il primo mito di backup.
Il backup è l'ultima linea di difesa per l'integrità del sistema. Se l'amministratore del database deve ripristinare il sistema del prodotto dai backup, significa che sono stati commessi molti errori nell'organizzazione del lavoro con un'alta probabilità. Non puoi considerare il backup come il modo principale per garantire l'integrità dei dati, no, è più come un sistema antincendio. È necessario un sistema antincendio. Deve essere configurato, testato e operativo. Ma se ha funzionato, allora questa di per sé è una grave emergenza con molte conseguenze negative.
Affinché il backup venga utilizzato solo per scopi "pacifici", utilizzare altri mezzi per garantire le prestazioni:
A seconda dei requisiti di disponibilità del sistema e del budget assegnato per questi scopi, è del tutto possibile scegliere soluzioni che ridurranno i tempi di inattività e il ripristino di emergenza di 1-2 ordini di grandezza. Non c'è bisogno di aver paura delle tecnologie di accessibilità: sono abbastanza semplici da imparare in pochi giorni con una conoscenza di base di MS SQL.
Ma, nonostante tutto, il backup è ancora necessario. Questo è lo stesso paracadute di riserva che puoi usare quando tutti gli altri mezzi di fuga falliscono. Ma, come un vero paracadute di riserva, per questo:
I dati in MS SQL sono solitamente memorizzati in file di dati (di seguito FD non è un'abbreviazione comunemente usata, ci saranno alcune altre abbreviazioni non molto comuni in questo articolo) con estensioni mdf o ndf. Oltre a questi file, esistono anche i registri delle transazioni (LT), che vengono memorizzati in file con estensione ldf. Non è raro che gli amministratori inesperti siano irresponsabili e impertinenti riguardo al VT, sia in termini di prestazioni che di affidabilità dello storage. Questo è un errore molto grossolano. Infatti, al contrario, se esiste un sistema di backup funzionante affidabile e si può allocare molto tempo per il ripristino del sistema, è possibile archiviare i dati su un RAID-0 veloce ma estremamente inaffidabile, ma il VT dovrebbe essere archiviato su una risorsa affidabile e produttiva separata (anche se sarebbe su RAID-1). Perché? Diamo un'occhiata più da vicino. Prenota immediatamente che la presentazione sia in qualche modo semplificata, ma sufficiente per una comprensione iniziale.
L'FD memorizza i dati in pagine di 8 kilobyte (che vengono combinate in estensioni di 64 kilobyte, ma questo non è essenziale). Microsoft SQL non garantisce che immediatamente dopo aver eseguito il comando per modificare i dati, queste modifiche cadranno nell'FD. No, è solo che la pagina in memoria è contrassegnata come "da salvare". Se il server dispone di risorse sufficienti, presto questi dati saranno su disco. Inoltre, il server funziona "in modo ottimistico" e se queste modifiche si verificano in una transazione, potrebbero arrivare sul disco prima che la transazione venga confermata. Cioè, nel caso generale, lavoro attivo Il FD contiene pezzi sparsi di dati incompiuti e transazioni incomplete per le quali non è noto se verranno cancellati o confermati. C'è un comando speciale "CHECKPOINT" che dice al server di scaricare "in questo momento" tutti i dati non salvati su disco, ma l'ambito di questo comando è piuttosto specifico. Basti dire che 1C non lo usa (non l'ho incontrato) e capire che durante il funzionamento l'FD di solito non è in uno stato coerente.
Per far fronte a questo caos, abbiamo solo bisogno di VT. Vengono scritti i seguenti eventi:
Tutte queste informazioni sono scritte indicando l'identificativo della transazione in cui si è verificata e in volume sufficiente per capire come passare dallo stato prima di questa operazione allo stato dopo questa operazione e viceversa (l'eccezione è il modello di ripristino con registrazione di massa) .
È importante che queste informazioni vengano scritte immediatamente sul disco. Fino a quando le informazioni non vengono registrate nel VT, il comando non è considerato eseguito. In una situazione normale, quando la dimensione del VT è sufficiente e quando non è molto frammentato, i record vengono scritti in esso in sequenza in piccoli record (non necessariamente multipli di 8 kb). Solo i dati realmente necessari per il ripristino entrano nel registro delle transazioni. In particolare Non vengono ricevute informazioni su quale testo della richiesta ha portato a modifiche, quale piano di esecuzione aveva questa richiesta, quale utente l'ha avviata e altre informazioni non necessarie per il ripristino. Qualche idea sulla struttura dei dati del registro delle transazioni può essere fornita dalla query
Seleziona * da::fn_dblog(null,null)
A causa del fatto che i dischi rigidi funzionano in modo molto più efficiente con le scritture sequenziali rispetto a un flusso caotico di comandi di lettura e scrittura e poiché i comandi SQL aspetteranno fino alla fine della scrittura sul VT, si pone la seguente raccomandazione:
Se esiste anche la minima possibilità, nell'ambiente di produzione i VT dovrebbero trovarsi su supporti fisici separati (da tutto il resto), preferibilmente con un tempo di accesso minimo per le scritture sequenziali e con la massima affidabilità. Per sistemi semplici RAID-1 va bene.
Se la transazione viene annullata, il server restituirà tutte le modifiche già apportate allo stato precedente. È per questo
La cancellazione di una transazione in MS SQL Server ha solitamente una durata paragonabile alla durata totale delle operazioni di modifica dei dati della transazione stessa. Cerca di non annullare le transazioni o decidi di annullare il prima possibile.
Se il server smette inaspettatamente di funzionare per qualche motivo, quando viene riavviato, analizzerà quali dati nell'FD non corrispondono a uno stato coerente (transazioni non registrate ma confermate e transazioni registrate ma annullate) e questi dati verranno corretti. Pertanto, se, ad esempio, hai iniziato a ricostruire gli indici di una tabella di grandi dimensioni e hai riavviato il server, quando lo riavvii, il rollback di questa transazione richiederà molto tempo e non è possibile interrompere questo processo.
Cosa succede quando il JT ha raggiunto la fine del file? È semplice: se c'è spazio libero all'inizio, inizierà a scrivere nello spazio libero all'inizio del file finché posto occupato. Come un nastro magnetico ad anello. Se non c'è spazio all'inizio, il server di solito tenta di espandere il file di registro delle transazioni, mentre per il server il nuovo pezzo allocato è un nuovo file di registro delle transazioni virtuale, che può essere molti nel file di transazione fisico, ma questo non è sufficiente per il backup. Se il server non riesce a espandere il file (esaurisce lo spazio su disco o è vietato espandere il VT nelle impostazioni), la transazione corrente verrà annullata con l'errore 9002.
Ops. E cosa bisogna fare affinché ci sia sempre un posto nello ZhT? È qui che arriviamo al sistema di backup e ai modelli di ripristino. Per annullare le transazioni e ripristinare il corretto stato del server in caso di arresto improvviso, è necessario memorizzare i record nel LT, a partire dall'avvio della prima transazione aperta. Questo minimo è scritto e memorizzato nel JT Necessariamente. Indipendentemente dal tempo, dalle impostazioni del server e dal desiderio dell'amministratore. Il server non può permettere che queste informazioni manchino. Pertanto, se apri una transazione in una sessione ed esegui azioni diverse in altre, il registro delle transazioni potrebbe terminare in modo imprevisto. La prima transazione può essere identificata con il comando DBCC OPENTRAN. Ma questo è solo il minimo necessario di informazioni. Quello che succede dopo dipende da modelli di recupero. Ce ne sono tre in SQL Server:
Esistono diversi miti associati ai modelli di recupero.
Il modello registrato in blocco per i database 1C è quasi inutile da utilizzare, quindi non lo considereremo ulteriormente. Ma la scelta tra Full e Simple sarà considerata più in dettaglio nella parte successiva.
Esistono tre tipi di backup in base al tipo di formazione:
Non confonderti qui: un modello di ripristino completo e un backup completo sono essenzialmente cose diverse. Per non confonderli, di seguito utilizzerò termini inglesi per il modello di ripristino e termini russi per i tipi di backup.
La copia completa e differenziale funziona allo stesso modo per Simple e Full. Il backup del registro delle transazioni è completamente assente da Simple.
Consente di ripristinare lo stato del database a un determinato momento (quello in cui è stato avviato il backup). Consiste in una copia impaginata della parte utilizzata dei file di dati e della parte attiva del registro delle transazioni per il tempo durante la creazione del backup.
Memorizza pagine di dati che sono cambiate dall'ultimo backup completo. Durante il ripristino, è necessario prima ripristinare un backup completo (in modalità NORECOVERY, verranno forniti esempi di seguito), quindi è possibile applicare una qualsiasi delle successive copie differenziali al "vuoto" risultante, ma, ovviamente, solo quelle effettuate prima del successivo backup completo. Questo può ridurre significativamente il volume spazio sul disco per archiviare il backup.
Punti importanti:
Contiene una copia del VT per un certo periodo. Di solito dal momento dell'ultimo RKZHT fino alla formazione dell'attuale RKZHT. RCRT consente di ripristinare lo stato in qualsiasi momento successivo, compreso nell'intervallo della copia di backup ripristinata, da una copia ripristinata in modalità NORECOVERY a qualsiasi momento compreso nel periodo della copia ripristinata del RT. Quando si crea un backup con parametri standard, lo spazio nel file di registro delle transazioni viene liberato (fino al momento dell'ultima transazione aperta).
È ovvio che RKZhT non ha senso nel modello Simple (quindi VT contiene solo informazioni dal momento dell'ultima transazione non chiusa).
Quando si utilizza RKZHT, sorge un concetto importante: catena continua di RKZhT. Questa catena può essere interrotta sia dalla perdita di alcune delle copie di backup di questa catena, sia dal passaggio del database a Simple e viceversa.
Avviso: un set di RCST è essenzialmente inutile a meno che non sia una catena contigua e l'ora di inizio dell'ultimo backup completo o differenziale riuscito deve essere dentro periodo di questa catena.
Idee sbagliate e miti comuni:
Lascia che ci sia un database di 1000 GB. Ogni giorno, il database cresce di 2 GB, mentre vengono modificati 10 GB di vecchi dati. Effettuati i seguenti backup
Con questo set, possiamo ripristinare i dati alle 0:00 in qualsiasi giorno dal 1 febbraio al 14 febbraio. Per fare ciò, dobbiamo prendere una copia completa di F1 per la settimana dall'1 al 7 febbraio o una copia completa di F2 per l'8-14 febbraio, ripristinarla in modalità NORECOVERY e quindi applicare una copia differenziale del giorno desiderato.
Supponiamo di avere lo stesso set di backup completi e differenziali dell'esempio precedente. Oltre a questo, ci sono i seguenti RKZHT:
Nota:
Nel caso più semplice, dobbiamo ripristinare:
Prima verrà ripristinato F2, poi D2.2, quindi RKZHT 6 fino alle 13:13:13 del 10 febbraio. Ma un vantaggio significativo del modello completo è che abbiamo una scelta: utilizzare l'ultima copia completa o differenziale o NON l'ultima. Ad esempio, se si scopre che la copia di D2.2 è danneggiata e dobbiamo ripristinare un momento prima delle 13:13:13 del 10 febbraio, per il modello Simple ciò significherebbe che possiamo ripristinare i dati solo su il momento D2.1. Con Full - "DON" T PANIC", abbiamo le seguenti opzioni:
Come puoi vedere, il modello completo ci offre più scelta.
Ora immagina di essere molto astuto. E un paio di giorni prima del fallimento (13:13:13 10 febbraio) sappiamo che ci sarà un fallimento. Stiamo ripristinando il database da un backup completo sul server adiacente, lasciando la possibilità di implementare gli stati successivi con copie differenziali o RKZHT, ovvero lasciato in modalità NORECOVERY. E ogni volta immediatamente dopo la formazione dell'RKZhT, lo applichiamo a questa base di riserva, lasciandola in modalità NORECOVERY. Oh! Perché, ora ci vorranno solo 10-15 minuti per ripristinare il database, invece di ripristinare un enorme database! Congratulazioni, abbiamo reinventato il meccanismo di spedizione dei log, uno dei modi per ridurre i tempi di inattività. Se trasferisci i dati in questo modo non una volta ogni tanto, ma costantemente, si verificherà il mirroring e se la base di origine attende fino all'aggiornamento della base del mirror, si tratta di mirroring sincrono, se non attende, quindi asincrono.
Puoi leggere ulteriori informazioni sugli strumenti ad alta disponibilità nella guida:
Puoi tranquillamente saltare questa sezione se sei annoiato dalla teoria e non vedi l'ora di provare le impostazioni di backup.
1C:Enterprise, infatti, non sa lavorare con i filegroup. C'è un singolo filegroup e basta. Infatti, un programmatore o amministratore di database MS SQL è in grado di inserire alcune tabelle, indici o anche parti di tabelle e indici in gruppi di file separati (nella versione più semplice, in singoli file). Ciò è necessario o per velocizzare l'accesso ad alcuni dati (mettendoli su supporti molto veloci), o viceversa, sacrificando la velocità per metterli su supporti più economici (ad esempio dati poco utilizzati ma voluminosi). Quando si lavora con i filegroup, è possibile crearne copie di backup separatamente ed è anche possibile ripristinarli separatamente, ma è necessario tenere conto del fatto che tutti i filegroup dovranno essere "raggiunti" in un momento facendo scorrere RKZHT.
Se una persona controlla il posizionamento dei dati in diversi gruppi di file, quando ci sono più file all'interno del gruppo di file, MS SQL Server inserisce i dati su di essi in modo indipendente (con un uguale volume di file, proverà in modo uniforme). Dal punto di vista dell'applicazione, viene utilizzato per parallelizzare le operazioni di I/O. E in termini di backup, c'è un altro punto. Per database molto grandi nell'era "pre-SQL 2008", era un problema tipico allocare una finestra continua per un backup completo e il disco di destinazione per questo backup potrebbe semplicemente non adattarsi. al massimo in modo semplice in questo caso si trattava di fare una copia di backup di ogni file (o filegroup) nella propria finestra. Ora, con la diffusione attiva della compressione dei backup, questo problema è diminuito, ma è comunque possibile tenere presente questa tecnica.
MS SQL Server 2008 ha una funzionalità super-mega-ultra. D'ora in poi, i backup possono essere compressi al volo. Ciò riduce la dimensione del backup del database 1C di 5-10 volte. E considerando che di solito la performance sottosistema del discoè un collo di bottiglia del DBMS, questo non solo riduce il costo dell'archiviazione, ma anche una potente accelerazione del backup (sebbene il carico sui processori aumenti, ma di solito la potenza del processore è abbastanza sufficiente sul server DBMS).
Se nella versione 2008 questa funzione era solo per l'edizione Enterprise (che è molto costosa), nel 2008 R2 questa funzione è stata data alla versione Standard, il che è molto piacevole.
Le impostazioni di compressione non sono trattate negli esempi seguenti, ma consiglio vivamente di utilizzare la compressione di backup a meno che non ci sia un motivo specifico per disattivarla.
Un backup infatti non è solo un file, è un contenitore piuttosto complesso che può archiviare molti backup. Questo approccio ha una storia molto antica (l'ho osservato personalmente dalla versione 6.5), ma al momento non ci sono motivi seri per gli amministratori di database "normali", in particolare database 1C, per non utilizzare "un backup - un file" approccio. Per lo sviluppo generale, è utile studiare la possibilità di inserire più backup in un file, ma molto probabilmente non dovrai usarlo (o se devi, quindi risolvere i blocchi di un aspirante amministratore che ha utilizzato questa opportunità in modo non qualificato).
SQL Server ha un'altra grande funzionalità. È possibile formare una copia di backup in parallelo a più ricevitori. Come semplice esempio, puoi eseguire il dump di una copia su un disco locale e contemporaneamente eseguire il dump in risorsa di rete. La copia locale è conveniente, poiché il ripristino da essa è molto più veloce, mentre la copia remota è in grado di sopravvivere molto meglio alla distruzione fisica del server del database principale.
Basta teoria. È ora di dimostrare con la pratica che tutta questa cucina funziona.
Questa sezione è costruita sotto forma di ricette già pronte con spiegazioni. Questa sezione è molto noiosa e lunga a causa delle immagini, quindi puoi saltarla.
La domanda sorge immediatamente, cos'altro è necessario? Sembra che tutto sia stato appena impostato e tutto funzioni come un orologio? Perché faticare con tutti i tipi di script? I piani di servizio non consentono:
I seguenti sono tipici comandi di backup
Backup completo con sovrascrittura del file esistente (se presente) e verifica dei checksum delle pagine prima della scrittura. Quando si crea un backup, viene conteggiata ogni percentuale di avanzamento
BACKUP DATABASE SU DISCO = N"C:\Backup\mydb.bak" CON INIT, FORMATO, STATISTICHE = 1, CHECKSUM
Allo stesso modo - copia differenziale
BACKUP DATABASE SU DISCO = N"C:\Backup\mydb.diff" CON DIFFERENZIALE, INIT, FORMAT, STATS = 1, CHECKSUM
Backup del registro delle transazioni
BACKUP LOG SU DISCO = N"C:\Backup\mydb.trn" CON INIT, FORMATO
Spesso è conveniente creare non una copia di backup alla volta, ma due. Ad esempio, uno può trovarsi localmente sul server (in modo che sia a portata di mano), e il secondo viene immediatamente formato in uno spazio fisicamente remoto e protetto dall'archiviazione avversa:
BACKUP DATABASE SU DISCO = N"C:\Backup\mydb.bak", SPECCHIO A DISCO = N"\\safe-server\backup\mydb.bak" CON INIT, FORMATO
Un punto importante che spesso viene trascurato: l'utente sotto il quale viene avviato il processo di MSSQL Server deve avere accesso alla risorsa "\\safe-server\backup\", altrimenti la copia fallirà. Se MSSQL Server è in esecuzione per conto del sistema, l'accesso deve essere concesso all'utente di dominio "server_name$", ma è comunque preferibile configurare correttamente MS SQL in modo che venga eseguito per conto di un utente appositamente creato.
Se non si specifica MIRROR TO , non saranno 2 copie speculari, ma una copia suddivisa in 2 file, secondo il principio dello striping. E ognuno di loro individualmente sarà inutile.
I server di database sono tra quelli chiave in qualsiasi organizzazione. Sono loro che memorizzano le informazioni e forniscono output su richiesta ed è estremamente importante salvare il database in qualsiasi situazione. La distribuzione di base di solito include le utilità necessarie, ma un amministratore che non ha mai incontrato un database dovrà fare i conti per un po 'di tempo con le peculiarità del lavoro per garantire l'automazione.
Per cominciare, scopriamo quali sono i backup in generale. Il server di database non è una normale applicazione desktop e per garantire l'implementazione di tutte le proprietà ACID (Atomic, Consistency, Isolated, Durable), vengono utilizzate numerose tecnologie e quindi la creazione e il ripristino di un database da un archivio ha il suo proprie caratteristiche. Esistono tre diversi approcci per il backup dei dati, ognuno con i propri pro e contro.
Con un backup logico, o SQL, (pg_dump, mysqldump, SQLCMD), viene creata un'istantanea istantanea del contenuto del database, tenendo conto dell'integrità transazionale e salvata come file con comandi SQL (è possibile selezionare l'intero database o singoli tables), con cui è possibile ricreare il database su un altro server. Ci vuole tempo (soprattutto per database di grandi dimensioni) per salvare e ripristinare, quindi molto spesso questa operazione non può essere eseguita e viene eseguita durante il carico minimo (ad esempio, di notte). Durante il ripristino, l'amministratore dovrà eseguire alcuni comandi per preparare tutto il necessario (creare un database vuoto, Conti E così via).
Backup fisico (livello sistema di file) - copia i file utilizzati dal DBMS per archiviare i dati nel database. Ma la semplice copia ignora i blocchi e le transazioni, che potrebbero essere archiviati e violati in modo errato. Se provi ad allegare questo file, sarà in uno stato incoerente e genererà errori. Per ottenere un backup aggiornato, il database deve essere arrestato (è possibile ridurre i tempi di inattività utilizzando rsync due volte: prima su uno in esecuzione, quindi su uno interrotto). Lo svantaggio di questo metodo è ovvio: non è possibile ripristinare determinati dati, ma solo l'intero database. Quando si avvia un database ripristinato da un archivio del file system, sarà necessario verificarne l'integrità. Qui vengono utilizzate varie tecnologie assistive. Ad esempio, in PostgreSQL, i log WAL (Write Ahead Logs) e funzione speciale(Point in Time Recovery - PITR), che consente di tornare a uno stato specifico del database. Con il loro aiuto, il terzo scenario è facilmente implementabile, quando un backup a livello di file system viene combinato con un backup di file WAL. Innanzitutto, ripristiniamo i file di backup del file system, quindi, utilizzando WAL, il database viene aggiornato. Questo è un approccio leggermente più complicato per l'amministrazione, ma non ci sono problemi con l'integrità del database e il ripristino dei database a un certo tempo.
Un backup logico viene utilizzato nei casi in cui è necessario eseguire una copia completa una tantum del database o nell'uso quotidiano non richiede molto tempo o spazio per creare una copia. Quando lo scaricamento dei database richiede molto tempo, è necessario prestare attenzione all'archiviazione fisica.
Licenza: GNU GPL
DBMS supportato: PostgreSQL
PostgreSQL supporta funzionalità di backup fisico e logico aggiungendo un altro livello di WAL (vedi barra laterale) che può essere chiamato backup continuo. Ma gestire più server utilizzando strumenti standard non è molto conveniente nemmeno per un amministratore esperto e, in caso di guasto, il conteggio arriva ai secondi.
Barman (backup and recovery manager) è uno sviluppo interno di 2ndQuadrant, una società che fornisce servizi basati su PostgreSQL. Progettato per il backup PostgreSQL fisico (la logica non supporta), l'archiviazione WAL e recupero rapido dopo gli incidenti. Supporta backup e ripristino remoti di più server, ripristino point-in-time (PITR), gestione WAL. SSH viene utilizzato per copiare ed inviare comandi a un host remoto, la sincronizzazione e il backup tramite rsync consentono di ridurre il traffico. Barman si integra anche con utilità standard bzip2, gzip, tar e simili. In linea di principio, puoi utilizzare qualsiasi programma di compressione e archiviazione, l'integrazione non richiederà molto tempo. Implementate varie funzioni di servizio e diagnostica che consentono di monitorare lo stato dei servizi e regolare la larghezza di banda. Gli script pre/post sono supportati.
Barman è scritto in Python e le policy di backup sono gestite utilizzando il simpatico file INI barman.conf, che può trovarsi in /etc o nella home directory dell'utente. La consegna include un modello già pronto con commenti dettagliati all'interno. Funziona solo su sistemi *nix. Per l'installazione su RHEL, CentOS e Scientific Linux, è necessario connettere EPEL, un repository che contiene pacchetti aggiuntivi. Gli utenti Debian/Ubuntu hanno a loro disposizione il repository ufficiale:
$ sudo apt-get install barman
Non sempre nel repository ultima versione, per installarlo dovrai fare riferimento ai testi di origine. Ci sono poche dipendenze e il processo è facile da capire.
Licenza: BSD
DBMS supportato: MySQL
Insieme a MySQL, vengono fornite le utilità mysqldump e mysqlhotcopy, che consentono di creare facilmente un dump del database, sono ben documentate e su Internet è possibile trovare un gran numero di esempi e frontend già pronti. Questi ultimi consentono al principiante di mettersi rapidamente al lavoro. Sypex Dumper è uno script PHP che consente di creare e ripristinare facilmente una copia del database Dati MySQL. Progettato per funzionare con database di grandi dimensioni, è molto veloce, chiaro e facile da usare. Sa come lavorare con oggetti MySQL: viste, procedure, funzioni, trigger ed eventi.
Un altro vantaggio, a differenza di altri strumenti che convertono in UTF-8 durante l'esportazione, è che Dumper esporta nella codifica nativa. Il file risultante occupa meno spazio e il processo stesso è più veloce. Un dump può contenere oggetti con codifiche diverse. Inoltre, è facile importare/esportare in più fasi, interrompendo il processo durante il caricamento. Al riavvio, la procedura riprenderà da dove era stata interrotta. Ci sono quattro opzioni per il ripristino:
Supporta la compressione delle copie (gzip o bzip2), l'eliminazione automatica dei vecchi backup, la visualizzazione del contenuto del file dump, il ripristino solo della struttura delle tabelle. Sono inoltre presenti funzioni di servizio per la gestione del database (creazione, eliminazione, controllo, ripristino del database, ottimizzazione, pulizia delle tabelle, utilizzo degli indici, ecc.), Nonché un file manager che consente di copiare i file sul server.

La gestione viene eseguita utilizzando un browser web, l'interfaccia AJAX è localizzata fuori dagli schemi e dà l'impressione di lavorare con un'applicazione desktop. È anche possibile eseguire lavori dalla console e nei tempi previsti (tramite cron).
Per far funzionare Dumper, avrai bisogno di un classico server L|WAMP, l'installazione è comune a tutte le applicazioni scritte in PHP (copia i file e imposta i permessi), e non sarà difficile nemmeno per un principiante. Il progetto fornisce documentazione dettagliata e tutorial video che dimostrano come lavorare con Sypex Dumper.
Esistono due edizioni: Sypex Dumper (gratuito) e Pro ($ 10). Il secondo ha più funzioni, tutte le differenze sono elencate sul sito.
Licenza:
DBMS supportato: Microsoft SQL Server
MS SQL Server è una delle soluzioni popolari e quindi è abbastanza comune. Il processo di backup viene creato utilizzando SQL Server Management Studio, Transact-SQL stesso e i cmdlet del modulo SQL PowerShell (Backup-SqlDatabase). Sul sito Web di MS, puoi trovare solo un'enorme quantità di documentazione che ti consente di comprendere il processo. La documentazione, sebbene completa, è molto specifica e le informazioni su Internet spesso si contraddicono a vicenda. Un principiante dovrà davvero esercitarsi prima, "riempiendosi la mano", quindi, nonostante tutto ciò che è stato detto, gli sviluppatori di terze parti hanno spazio per voltarsi. Oltretutto versione gratuita SQL Server Express non vanta strumenti di backup integrati. Per più prime versioni MS SQL (prima del 2008) puoi trovare utilità gratuite, come il backup di SQL Server , ma la maggior parte di questi progetti è già stata commercializzata, sebbene spesso offrano tutte le funzionalità per un importo simbolico.

Ad esempio, lo sviluppo di SQL Backup And FTP e One-Click SQL Restore segue il principio imposta e dimentica. Con un'interfaccia molto semplice e intuitiva, consentono di creare copie di database MS SQL Server (incluso Express) e Azure, salvare crittografati e file compressi all'FTP e servizi cloud(Casella personale, Casella, Google Drive, MS SkyDrive o Amazon S3), il risultato può essere visualizzato immediatamente. È possibile avviare il processo sia manualmente che in base alla pianificazione, inviare un messaggio sul risultato dell'attività tramite e-mail, avviare script utente.
Sono supportate tutte le opzioni di backup: completo, differenziale, registro delle transazioni, copia di una cartella con file e molto altro. I vecchi backup vengono eliminati automaticamente. Per connettersi all'host virtuale, viene utilizzato SQL Management Studio, anche se questo può essere sfumato e non funzionerà in tutte queste configurazioni. Cinque versioni sono disponibili per il download - da Gratuito al fantasioso Prof Lifetime (solo $ 149 al momento della stesura di questo articolo). La funzionalità gratuita è sufficiente per piccole reti, in cui sono installati uno o due server SQL, tutte le funzioni di base sono attive. Il numero di database di backup, la possibilità di inviare file a Google Drive e SkyDrive e la crittografia dei file sono limitati. L'interfaccia, sebbene non localizzata, è molto semplice e comprensibile anche per un principiante. Devi solo connetterti al server SQL, dopodiché verrà visualizzato un elenco di database, dovresti contrassegnare quelli che ti servono, configurare l'accesso alle risorse remote e specificare il tempo per il completamento dell'attività. E tutto questo in una finestra.
Ma ce n'è uno "ma". Il programma stesso non è progettato per ripristinare gli archivi. Per fare ciò, viene offerta un'utilità di ripristino SQL con un clic gratuita separata, che comprende anche il formato creato dal comando BACKUP DATABASE. L'amministratore deve solo specificare l'archivio e il server su cui ripristinare i dati e premere un pulsante. Ma in scenari più complessi, dovrai usare RESTORE.

La creazione di una copia di backup e il ripristino di un DBMS presenta le proprie differenze che devono essere prese in considerazione, soprattutto quando si trasferisce un archivio su un altro server. Ad esempio, analizziamo alcune delle sfumature di MS SQL Server. Per archiviare utilizzando Transact-SQL, utilizzare il comando BACKUP DATABASE (c'è anche un comando delta DIFFERENTIAL) e il log delle transazioni BACKUP LOG.
Se il backup viene distribuito su un server diverso, è necessario assicurarsi che siano presenti le stesse unità logiche. In alternativa, è possibile impostare manualmente i percorsi corretti per i file del database utilizzando l'opzione WITH MOVE del comando RESTORE DATABASE.
Una situazione semplice è il backup e il trasferimento di database ad altre versioni di SQL Server. Questa operazione è supportata, ma nel caso di SQL Server funzionerà se la versione del server su cui è distribuita la copia è uguale o più recente di quella su cui è stata creata. E c'è una limitazione: non più di due versioni più recenti. Dopo il ripristino, il database sarà in modalità compatibilità con la versione da cui è stata effettuata la transizione, ovvero non saranno disponibili nuove funzionalità. Questo è facile da risolvere modificando COMPATIBILITY_LEVEL. Può essere fatto con Guida dell'interfaccia grafica o SQL.
ALTER DATABASE MyDB SET COMPATIBILITY_LEVEL = 110;
È possibile determinare su quale versione è stata creata la copia osservando l'intestazione del file di archivio. Per non sperimentare, quando si passa a nuova versione SQL Server dovrebbe eseguire l'utilità gratuita Microsoft Upgrade Advisor.
Licenza: commerciale, esiste una versione gratuita
DBMS supportato: Oracle 9-11, XE, MySQL, MariaDB, PostgreSQL e MS SQL Server
Quando devi gestire più tipi di DBMS, le mietitrebbie sono indispensabili. La scelta è ampia. Ad esempio, Iperius è un programma di backup di file leggero, molto facile da usare ma potente che ha la capacità di eseguire il backup a caldo dei database senza interruzioni o blocchi. Fornisce backup completo o incrementale. Può creare immagini disco complete per la reinstallazione automatica dell'intero sistema. Supporta il backup su NAS, dispositivi USB, streamer, FTP/FTPS, Google Drive, Dropbox e SkyDrive. Supporta la compressione zip senza limiti di dimensione del file e la crittografia AES256, eseguendo script e programmi esterni. Include un'utilità di pianificazione delle attività molto funzionale, è possibile eseguire più attività in parallelo o in sequenza, il risultato viene inviato alla posta elettronica. Sono supportati numerosi filtri, variabili per la personalizzazione di percorsi e impostazioni.

La funzionalità di caricamento FTP semplifica l'aggiornamento delle informazioni su più siti Web. Apri file viene eseguito il backup utilizzando la tecnologia VSS (Volume Shadow Copy), che consente di eseguire un backup a caldo non solo dei file DBMS, ma anche di altre applicazioni. Per Oracle viene utilizzato anche lo strumento di backup e ripristino RMAN (Recovery Manager). Per non sovraccaricare il canale, è possibile regolare la larghezza di banda. La gestione del backup e del ripristino viene eseguita utilizzando la console locale e web. Tutte le funzioni sono in bella vista, quindi per impostare un'attività è necessaria solo una comprensione del processo, non è nemmeno necessario esaminare la documentazione. Basta seguire le istruzioni della procedura guidata. Puoi anche notare l'account manager, che è molto comodo con un gran numero di sistemi.
Le funzioni di base sono offerte gratuitamente, ma la possibilità di ridondanza del database è inclusa solo nelle versioni Advanced DB e Full. Supporta l'installazione da XP a Server Windows 2012.
Licenza: una pubblicità
DBMS supportato: Oracle, MySQL, IBM DB2 (7–9.5) e MS SQL Server
Uno dei più potenti sistemi di gestione di database relazionali è IBM DB2, che ha caratteristiche di scalabilità uniche e supporta molte piattaforme. Viene fornito in diverse edizioni, che sono costruite sulla stessa base e differiscono funzionalmente. L'architettura del database DB2 consente di gestire quasi tutti i tipi di dati: documenti, XML, file multimediali e così via. DB2 Express-C gratuito è particolarmente popolare. Il backup è molto semplice:
Esempio di database di backup db2
O uno snapshot utilizzando la funzione Advanced Copy Services (ACS):
db2 backup db sample use snapshot
Ma dobbiamo ricordare che nel caso di snapshot non possiamo ripristinare (db2 recovery db) singole tabelle. Ci sono opportunità per il backup automatico e molto altro. I prodotti sono ben documentati, sebbene i manuali siano rari su Internet in lingua russa. Inoltre, non tutte le soluzioni speciali possono trovare supporto per DB2.
Per esempio, Backup a portata di mano consente di eseguire il backup di diversi tipi di server di database e salvare i file su quasi tutti i supporti ( HDD, CD/DVD, cloud e archiviazione di rete, FTP/S, WebDAV e altri). È possibile eseguire il backup dei database tramite ODBC (solo tabelle). È una delle poche soluzioni che supporta DB2 e porta anche il logo "Ready for IBM DB2 Data Server Software". L'intera procedura viene eseguita utilizzando una procedura guidata convenzionale, in cui è sufficiente selezionare l'elemento desiderato e creare un'attività. Il processo di configurazione stesso è così semplice che anche un principiante può capirlo. È possibile creare più processi che verranno eseguiti in base a una pianificazione. Il risultato viene registrato e inviato via e-mail. Non è necessario arrestare il servizio mentre il processo è in esecuzione. L'archivio viene automaticamente compresso e crittografato, il che ne garantisce la sicurezza.
Il lavoro con DB2 è supportato da due versioni di Handy Backup: Office Expert (locale) e Server Network (rete). Funziona su computer che eseguono Win8/7/Vista/XP o 2012/2008/2003. Il processo di distribuzione in sé non è difficile per nessun amministratore.
Continuiamo a parlare di backup e oggi impareremo creare un archivio Basi Microsoft SQL Server 2008. Considereremo tutto come al solito con esempi utilizzando sia l'interfaccia grafica che utilizzando la query SQL, e imposteremo anche l'automatico creazione di un backup utilizzando un file batch.
Non torneremo sulla questione dell'importanza del backup del database, poiché abbiamo già sollevato questo argomento più di una volta, ad esempio, nei materiali:
E nell'ultimo articolo, ho detto che prenderemo in considerazione la possibilità di creare un archivio sul DBMS MS SQL Server 2008, quindi ora lo faremo.
E poiché c'era già molta teoria, passiamo subito alla pratica, ovvero alla creazione di una base di riserva.
Nota! Come si evince dal titolo dell'articolo, realizzeremo l'archivio sul DBMS Microsoft SQL 2008 utilizzando Management Studio. Il server si trova in locale. Sistema operativo Windows 7.
Decidiamo che creeremo un archivio di un database di test chiamato "test". Dall'inizio fino in fondo GUI, e nel processo, scriveremo uno script in modo che in futuro possiamo semplicemente eseguirlo e non essere più distratti dall'inserimento di tutti i tipi di parametri.
Apri Management Studio, espandi « Banca dati» , selezionare la base desiderata, fare clic clic destro mouse su di esso, selezionare Attività->Backup

Vedrai la finestra " Backup del database”, dove è possibile impostare i parametri di archiviazione. Ho solo dato un nome Serie di backup", e ho anche cambiato il nome dell'archivio e il percorso, poiché per impostazione predefinita verrà creato nella cartella Programmi, ad esempio, avevo il percorso predefinito
C:\Programmi\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\Backup\
Ad esempio, l'ho cambiato in C:\temp\ e ho chiamato l'archivio test_arh.bak

Anche se vai alla scheda « Opzioni», quindi puoi impostare l'impostazione per sovrascrivere tutti i set di dati, ora spiegherò di cosa si tratta. Se lasci tutto così com'è, ad es. aggiungi a un set di dati esistente, avrai un file di backup, ma con diverse istanze di set di dati, ad es. durante il ripristino, seleziona semplicemente il set di cui hai bisogno. E se metti " Sovrascrivi tutti i set di backup esistenti”, allora il set sarà sempre lo stesso, quindi in questo caso bisognerà creare archivi (diciamo giornalieri) con nomi diversi. L'ho impostato per sovrascrivere, perché diciamo, in futuro, ho intenzione di creare archivi per ogni giorno con la data nel nome di questi archivi, al fine di copiare rapidamente il backup di cui ho bisogno per una certa data in qualsiasi posto se necessario .

E a proposito, a questo punto, dopo aver inserito tutti i parametri, puoi creare uno script per registrarlo e usarlo in seguito. Per fare ciò, è sufficiente fare clic in alto Scenario».
E come risultato di questa azione, aprirai una finestra di query, in cui ci sarà un codice per questo script. Ci torneremo un po 'più tardi, ma per ora fai clic su "OK" e al termine dell'operazione vedrai una finestra in cui verrà indicato il risultato del backup, se tutto va bene, verrà visualizzato il seguente messaggio apparire

Se hai fatto tutto come sopra quelli. cliccato su "Copione"), quindi hai aperto una finestra di query, che in realtà contiene la richiesta di creazione dell'archivio stessa, ma la rifaremo un po ', dato che ho detto che abbiamo intenzione di eseguirla ogni giorno, in modo che il nome sia appropriato, scriveremo questo Istruzione SQL.
DICHIARA @percorso COME VARCHAR(200) SET @percorso = N"C:\temp\test_arh_" + CONVERT(varchar(10), getdate(), 104) + ".bak" BACKUP DATABASE SU DISCO = @percorso SENZA FORMATO, INIT, NAME = N"Test database", SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO
E ora se lo eseguiamo, creeremo un backup del database con il nome test_arh_ La data corrente.bak
Per questi scopi, MS SQL 2008 ha occasione speciale intitolato " Piani di servizio”, dove puoi semplicemente impostare una pianificazione per la creazione di un backup del database, ma suggerisco di utilizzare un file bat per questi scopi per configurarlo nello scheduler e farlo funzionare ogni giorno ed eseguire il backup del database.
Per fare questo, copia Istruzione SQL, che abbiamo esaminato sopra, e incollalo nel blocco note ( Consiglio Notepad++), quindi salva con l'estensione .sql quelli. questo script verrà eseguito su MS Sql 2008. Quindi dovremo scrivere un file batch in modo che si connetta al server SQL ed esegua il nostro script. Scrivi anche nel blocco note:
SET cur_date=%date:~6.4%%date:~3.2%%date:~0.2% osql -S localhost -i C:\temp\test.sql -o C:\temp\%cur_date %_log_sql.log -E
dove, ho creato una variabile cur_date per memorizzare la data corrente in essa, quindi mi collego a server locale, tramite l'utilità osql, che utilizza ODBC ed esegue il nostro script ( L'ho chiamato test.sql), e scrivi anche un registro, dove e solo avevamo bisogno della nostra variabile, tutto qui, salvo con l'estensione .bat, creiamo un'attività nello scheduler e possiamo dire che ci dimentichiamo del processo di archiviazione del database, beh, controlliamo solo periodicamente se l'archivio è stato creato o meno.
Per le basi, questo è abbastanza, ora sai come eseguire il backup dei database su un server SQL 2008, nel prossimo articolo vedremo come ripristinare un database su MS SQL Server 2008. Nel frattempo, è tutto ! Buona fortuna!
E anche: backup SQL, backup 1C.
Il server 1C contiene i dati nel database, che si trova sul server SQL. Oggi stiamo considerando MS SQL 2005/2008.
Per garantire che i dati non vadano persi in caso di masterizzazione del disco del server o altre situazioni di forza maggiore, è necessario eseguire i backup fin dall'inizio.
Ovviamente nessuno vuole creare penne ogni giorno Backup del database SQL 1C. Ci sono strumenti automatici per questo. Conosciamoli.
Configurazione di BackupSQL
L'impostazione di Backup SQL per un database 1C non è diversa dall'impostazione di un backup per qualsiasi altro database.
Per configurare, eseguire MS SQL Management Studio. Questo programma è nel gruppo di programmi MS SQL.
Aggiunta di un'attività di backup del database SQL 1C
Le attività per il backup automatico dei database SQL si trovano nel ramo Piani di gestione/manutenzione.

Per aggiungere una nuova attività di backup, fare clic con il pulsante destro del mouse sul gruppo Piani di manutenzione e selezionare Nuovo piano di manutenzione.

Immettere il nome dell'attività. Il nome conta solo per te. Per ogni evenienza, è meglio usare caratteri inglesi.
Impostazione di un processo di backup del database SQL 1C
Si aprirà il Job Editor. Si noti che i lavori possono eseguire varie operazioni con il database e non solo i backup.
L'elenco delle opzioni per le operazioni viene visualizzato in basso a sinistra. Selezionare l'attività di backup del database facendo doppio clic o semplicemente trascinando verso destra.

Notare la freccia. Puoi trascinare e rilasciare diverse operazioni diverse o identiche e collegarle con le frecce. Quindi verranno eseguite diverse attività contemporaneamente nella sequenza specificata dall'utente.

Nella finestra delle impostazioni, seleziona i database SQL 1C richiesti (puoi averne diversi o uno alla volta).

Selezionare la posizione in cui salvare il backup del database SQL 1C. È necessario selezionare un disco rigido fisicamente diverso. Dal punto di vista organizzativo, puoi selezionare la casella "Crea sottocartelle".

Ora impostiamo la pianificazione del backup. La pianificazione di backup predefinita è stata aggiunta da sola. Ma puoi aggiungere più pianificazioni (ad esempio, una giornaliera, una settimanale, ecc.). Fare clic sul pulsante delle impostazioni di pianificazione del backup.

Lo screenshot mostra un esempio di un database SQL di backup giornaliero 1C alle 3 del mattino.

Per rendere piacevole e comprensibile la pianificazione del backup nell'elenco, è possibile modificarla.

Salvataggio di un processo di backup del database SQL 1C
Fai clic su masterizza. L'attività verrà visualizzata sul lato sinistro dell'elenco.
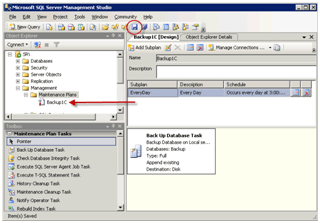
È importante! Verificare che l'attività di backup del database SQL sia stata creata correttamente. Per fare ciò, fare clic con il pulsante destro del mouse sull'attività e selezionare Esegui.
Di conseguenza, dovrebbe apparire un file di backup nel percorso specificato. Se qualcosa non va, elimina l'attività (Del) e ricomincia dall'inizio.
Consideriamo una situazione indesiderabile. Vale a dire: per qualche motivo, il database non è riuscito. Cosa abbiamo? Una copia integrale, una copia differenziale per ieri, ma ci sono anche dati per oggi, era davvero necessario fare una copia differenziale ogni ora? - NO! Mangiare Registro delle transazioni.
Il registro delle transazioni è un registro che registra tutte le transazioni e tutte le modifiche al database apportate da ciascuna transazione. Quelli. qualsiasi azione con il database viene registrata passo dopo passo nel registro. Ogni record viene contrassegnato dal DBMS per il completamento della transazione, completata o meno. Con il suo aiuto, puoi ripristinare lo stato del database non solo dopo un errore, ma anche in caso di azioni impreviste con i dati. Rollback fino a un certo momento. Come per il database, è necessario eseguire il backup del registro delle transazioni, completo, differenziale, incrementale. Per ripristinare parte del registro delle transazioni dopo un errore tra i backup, è necessario eseguire il backup dell'ultima parte del registro, che, di fatto, è il punto di finalizzazione del backup. Eseguito dopo un incidente, come punto di conto alla rovescia.
Pertanto, per ripristinare il database dopo un arresto anomalo, è necessaria una copia completa aggiornata del database, una copia differenziale del database e una copia del registro delle transazioni.
Per il database stesso, sono disponibili 3 modelli di ripristino: semplice, completo e con registrazione di massa. Prendere in considerazione:
Consideriamo la catena di backup più rilevante: backup completo - una volta alla settimana, backup differenziale - una volta al giorno, backup del registro delle transazioni - una volta all'ora.
Esistono diverse opzioni per la creazione di backup:
Considera la prima opzione come la più utilizzabile. Per questo, vengono utilizzati Windows Server 2008 R2 Enterprise e MS SQL Server 2008 Eng.
Quindi diciamo che abbiamo un database TECH:
Passiamo allo strumento per la creazione di posti di lavoro:

Tre tasti destro del mouse e chiama Master Job:
Selezioniamo la casella di controllo "Esecuzione separata di ogni attività", stiamo eseguendo solo un'azione

Il maestro è senza turbante, ma la cosa principale non è la dimensione del turbante)) Selezioniamo il tipo di desiderio, nel nostro caso - prenotazione completa:

Il Maestro Joba, come si è scoperto, è un po' ebreo, quindi chiede di nuovo:

"Vale la pena scegliere opzioni aggiuntive, oh giovane paddawan!":
qui selezioniamo il database, il periodo di archiviazione del backup, l'indirizzo (nastro o disco), il percorso di salvataggio e, soprattutto, l'utilità di pianificazione!

"Non dimenticare il database quando scegli il tuo. Concentra il tuo potere e scegli il database":

"Troppo velocemente hai fretta di creare un'attività, fai clic sul pulsante in basso con il nome Pianifica - Definisci".
Sobsno, task scheduler, dove selezioniamo il tipo (ripetizione, una volta, ecc.), giorno, ora, tipo di inizio:
Questo è tutto, creato. Il Maestro Joba è fresco e verde. Guardiamo lo stato in Piani di manutenzione:

Per i paranoici, non aver paura di ammetterlo allo specchio, vale la pena esaminare l'anima di SQL Server Agent - Job Activity Monitor, Job Master mostrerà tutto in dettaglio:

Ora, se le condizioni date sono soddisfatte, dovrebbe creare backup completo DB. In base allo stesso principio, vengono creati un backup differenziale e un backup del registro delle transazioni (questi elementi secondari si trovano sotto "Backup completo" nell'elenco di selezione dei processi).
Torci le orecchie con MSSQL come preferisci, non svitare
L'articolo successivo illustra la creazione con Transact-SQL e un paio di esempi.








