Maskinerna måste fungera.
Folk måste tänka.
Kurs "Professionell Internetsökning" - bekvämt sätt lär dig att kompetent och effektivt söka och hitta nödvändig information på Internet.
Vad har hänt professionell söka?
Internet paradoxär att informationen blir mer och mer alltmer, men hitta nödvändig information blir det blir svårare. Professionell sökning är effektiv sökning nödvändig Och pålitlig information.
I den moderna världen blir information kapital, och Internet blir ett bekvämt sätt att erhålla den, varför förmågan att hitta värdefull information kännetecknar en person som proffs av hög klass. En professionell sökning ska alltid vara effektiv. Dessutom, under sökningen letar proffs inte bara efter platsen där informationen lagras, utan utvärderar också resursens auktoritet, relevans, riktighet och fullständighet av den publicerade informationen. Internetheuristik hjälper oss med detta - en uppsättning användbara sökregler, urvalskriterier och utvärdering av nätverksinformation.
Vad kommer du att lära dig och vad kommer du att lära dig?
Har du letat och inte hittat den? Då kommer kursen att vara mycket användbar för dig. Du kommer att få omfattande sökinstruktioner något som redan finns på Internet, men vid första anblicken verkar det som att det helt enkelt är omöjligt att hitta det... Kanske! Du kommer att få reda på det hur man söker för att hitta! Varje lektion är baserad på en kombination av kunskap och erfarenhet, alla mottagna kunskap prövas i handling.
Under kurslektionerna Du kommer att få reda på det, hur det moderna internet utvecklas och hur elektronisk information distribueras, hur kataloger skapas och hur sökmotorer fungerar, varför metasökmotorer behövs och var den ”dolda” webben kom ifrån, hur forum skiljer sig från bloggar och vad insamling är.
Under workshops Du kommer att lära dig använd frågespråket korrekt, välj nyckelord på ett klokt sätt, hitta information på den "dolda" webben, hitta nödvändiga bilder och filer, utvärdera opinionen i bloggosfären, sök personlig information, och viktigast av allt - att korrekt bedöma tillförlitligheten, relevansen och fullständigheten hos den hittade informationen.
Internetsökningskursen gör att du kan avsevärt utveckla din kognitiva, informations- och kommunikationsförmåga.
Vilka ämnen behandlas i kursen Professional Search?
Målet med kursen är att lära ut möjligheter och finesser i modern sökning professionell information på Internet.
Varje lektion (modul) inkluderar föreläsning, seminarium i ett forumformat, testa att behärska det material som omfattas, samt flera övningar och sökuppgifter.
Den uppdaterade kursen kommer att innehålla veckovisa entimmes webbseminarier - interaktiva virtuella onlineseminarier tillägnad att diskutera nyckeluppgifterna för professionell internetsökning.
Varje utbildningsmodul levereras användbara ytterligare material om kursämnen och åhörarkopior som är bekväma att skriva ut.
Den tematiska planen för kursen består av 10 sammanlänkade moduler:
1. Internet: historia, teknik och internetforskning.
2. Informationssökning. Sök i kataloger.
3. System för informationssökning. IPS-närbild (Google, Yandex och andra).
4. Metasökmotorer och program.
5. Internet Help Desk: faktasökning i uppslagsverk, uppslagsböcker, ordböcker.
6. Bibliografisk sökning: bibliotek, kataloger, program.
7. Dokumentär sökning: elektroniska dokument, elektroniska bibliotek, elektroniska tidskrifter.
8. "Dold" webb: Sök i multimedia, databaser, kunskapsbaser och filer.
9. Sök nyheter(bloggar och forum), kontakter, institutioner, insamlingar.
10. Strategier informationsinhämtning : Generalisering av Internetheuristiska färdigheter.
Varför är kursen distansundervisning?
Distanskursen har en helhet ett antal fördelar.
För det första tilldelas varje lektion inte en eller två akademiska timmar per vecka, utan hela veckan. Du kan bemästra och tillgodogöra dig föreläsningsmaterial, utföra övningar och sökuppgifter utan brådska.
För det andra, distanskurs interaktiv. Det gör att du alltid kan fråga, förtydliga, ta reda på av läraren vad du tycker är viktigt. Din fråga kommer inte att förbli obesvarad, och komplexa sökuppgifter kan diskuteras i grupp för att utvärdera varje färdighet i jämförelse.
För det tredje kan du studera vid en tidpunkt som passar dig och du behöver inte slösa tid på att resa till klasser. Dessutom kan du studera var som helst i världen där det finns tillgång till Internet.
Vad är par för kursen?
Kursen "Internetheuristik" kommer att pågå i en månad och kommer att bestå av 10 moduler, varje modul består av "kvanta" lektioner - de låter dig behålla den takt som krävs för att bemästra nytt material). Pris för varje modul – endast 300 rubel, för alla klasser betalar du endast 3000 rubel. Observera att du inte behöver köpa ytterligare läroböcker. Om du framgångsrikt slutför kursen kommer du att få ett certifikat från Moscow State University för att ha genomfört kursen "Professionell Internetsökning".
Om du vill lära dig att vara påhittig på Internet måste du välja en lämplig tidpunkt för att gå kursen och registrera dig (klicka bara på anmälningslänken mittemot den lämpliga tidluckan högst upp på sidan)!
Efter registreringen har du fortfarande tid att tänka och fatta ett slutgiltigt beslut. Förresten, du kan träffas
I mitten av 2015 hade det globala Internet redan anslutit 3,2 miljarder användare, det vill säga nästan 43,8 % av jordens befolkning. Som jämförelse: För 15 år sedan var endast 6,5 % av befolkningen Internetanvändare, det vill säga antalet användare har ökat mer än 6 gånger! Men vad som är mer imponerande är inte de kvantitativa, utan de kvalitativa indikatorerna för utbyggnaden av implementeringen av internetteknik inom olika områden av mänsklig aktivitet: från global kommunikation av sociala nätverk till hushållsinternetsaker. Mobilt internet har gett användarna möjlighet att vara online utanför kontoret och hemma: på resande fot, utanför staden, i naturen.
För närvarande finns det hundratals system för att söka information på Internet. De mest populära av dem är tillgängliga för de allra flesta användare eftersom de är gratis och lätta att använda: Google, Yandex, Nigma, Yahoo!, Bing..... Mer erfarna användare"avancerad sökning"-gränssnitt, specialiserade sökningar "av sociala nätverk", enligt nyhetsflöden och köp- och försäljningsannonser... Men alla dessa underbara sökmotorer har en betydande nackdel, som jag redan noterat ovan som en fördel: de är gratis.
Om investerare investerar miljarder dollar i utvecklingen av sökmotorer, så uppstår en helt lämplig fråga: var tjänar de pengar?
Och de tjänar pengar, i synnerhet genom att tillhandahålla som svar på användarförfrågningar inte så mycket information som skulle vara användbar ur användarens synvinkel, utan den som ägarna av sökmotorer anser vara användbar för användaren. Detta görs genom att manipulera ordningen i vilken listor med svar på användarnas sökfrågor presenteras. Här är öppen reklam av vissa Internetresurser, och dold manipulation av relevansen av svar baserat på kommersiella, politiska och ideologiska intressen hos ägarna av sökmotorer.
Därför, bland professionella specialister på att söka information på Internet, är problemet med relevanta sökmotorresultat mycket relevant.
Relevans är överensstämmelsen mellan dokument som hittas av ett informationshämtningssystem och användarens informationsbehov, oavsett hur fullständigt och hur exakt detta informationsbehov uttrycks i själva informationsbegäran. Detta är volymförhållandet användbar information till den totala mängden mottagen information. Grovt sett är detta sökeffektivitet.
Specialister som gör kvalificerade sökningar efter information på Internet måste göra vissa ansträngningar för att filtrera sökresultaten och rensa bort onödig information "brus". Och för detta ändamål används sökverktyg professionell nivå.
Ett av dessa professionella system är det ryska programmet FileForFiles & SiteSputnik (SiteSputnik).
Framkallare Alexey Mylnikov från Volgograd.
"Programmet FileForFiles & SiteSputnik (SiteSputnik) är utformat för att organisera och automatisera professionell sökning, insamling och övervakning av information som publiceras på Internet. Särskild uppmärksamhet ägnas åt att få ny inkommande information om ämnen av intresse. Flera informationsanalysfunktioner har implementerats."
Övervakning och kategorisering av informationsflöden
Först några ord om övervaka informationsflöden, varav ett specialfall är övervakning av media och sociala nätverk:
- användaren anger de källor som kan innehålla den nödvändiga informationen och reglerna för att välja denna information;
- programmet laddar ner färska länkar från källor, befriar deras innehåll från skräp och upprepningar och ordnar dem i sektioner enligt reglerna.
För att se live en enkel men verklig övervakningsprocess, som involverar 6 källor och 4 rubriker:- öppna demoversionen av programmet;
- klicka sedan på knappen i fönstret som visas Tillsammans;
- och när WebbplatsSputnik kommer att genomföra detta projekt i realtid, du:
— i listan "Clean Stream" kommer du att se all ny information från källor,
- i avsnittet "Efter begäran" - endast ekonomiska och finansiella nyheter som uppfyller regeln,
- i rubrikerna "Om presidenten", "Om premiären" och "Centralbanken", - information om relevanta objekt.
I riktiga projekt kan du använda nästan valfritt antal källor och rubriker.
Du kan skapa dina första fungerande projekt på några timmar och förbättra dem under drift.
Den beskrivna informationsbehandlingen är tillgänglig i SiteSputnik Pro+News-paketet och högre.
Att bekanta sig med möjligheterna SiteSputnik Pro(grundläggande version av programmet) :
- öppna demoversionen av programmet;
- ange din första begäran, till exempel ditt fullständiga namn, som jag gjorde:
och klicka på knappen Söka.
- Programmet (se skylten som SiteSputnik byggde) kommer att ställa frågor om några sekunder 7 källor, öppnas i dem 24 söksidor, kommer att hitta 227 relevanta länkar, kommer att ta bort dubbletter av länkar och från de återstående 156 unik lista med länkar "Enande".
Totalt: antal unika länkar - 156 , dubbletter av länkar - 46 %.
Namn
Källa
Beställd
sidor
Nedladdat
sidor
Hittade
länkar
Tid
söka
Effektivitet
söka
Länkar
Ny
Effektivitet
NyYandex 5 5 50 0:00:05 32% 0 0 5 5 44 0:00:03 28% 0 0 Yahoo 5 5 50 0:00:05 32% 0 0 Vandrare 5 4 56 0:00:07 36% 0 0 MSN (Bing) 5 3 23 0:00:04 15% 0 0 Yandex.Bloggar 5 1 1 0:00:01 1% 0 0 Google.Bloggar 5 1 3 0:00:01 2% 0 0 Total: 35 24 227 0:00:26 — 0 0 - (! ) Upprepa din begäran efter några timmar eller dagar, så ser du bara nya länkar som förekom i källorna för denna tidsperiod. I de två sista kolumnerna i tabellen kan du se hur många nya länkar varje källa kom med och dess effektivitet i termer av "nyhet". När en fråga exekveras flera gånger, en lista som endast innehåller nya länkar , skapas i förhållande till alla tidigare exekveringar av denna begäran. Det verkar elementärt och önskad funktion, men författaren känner inte till något program där det är implementerat.
- (!! ) De beskrivna funktionerna stöds inte bara för individuella förfrågningar, utan också för hela begära paket :
Paketet som du ser består av sju olika frågor som samlar in information om Vasily Shukshin från flera källor, inklusive sökmotorer, Wikipedia, exakt sökning i Yandex-nyheter, metasök och sök efter omnämnanden på TV- och radiostationer. Till manuset TV och radio inkluderar: "Channel One", "TV Russia", NTV, RBC TV, "Echo of Moscow", radiobolaget "Mayak", ... och andra informationskällor. Varje källa har sitt eget sök- eller surfdjup på sidor. Det är listat i den tredje kolumnen.
Batchsökning låter dig utföra omfattande sökningar med ett klick insamling av information på ett givet ämne.
Separat lista nya länkar, vid upprepade körningar av paketet, kommer endast att innehålla länkar som inte tidigare hittades.
Kom ihåg vad och när du frågade Internet och vad det svarade dig Inget behov- allt sparas automatiskt i bibliotek och i programdatabaser.
Jag upprepar att de funktioner som beskrivs i det här stycket är helt inkluderade i paketet SiteSpunik Pro.
Mer information i instruktionerna: SiteSputnik Pro för nybörjare.
Ganska ofta ställs användaren inför följande uppgift. Du måste ta reda på vad som finns på Internet om ett specifikt objekt: en person eller ett företag. Till exempel när du anställer en ny medarbetare eller när en ny motpart dyker upp så vet du alltid hela namnet, företagsnamnet, telefonnummer, INN, OGRN eller OGRNIP, du kan även ta ICQ, Skype och lite annan data. Därefter använder du ett anrop till en speciell programfunktion WebbplatsSputnik "Samla information om objektet" (utrustning SiteSputnik Pro+Objekt):Du anger de uppgifter du känner till, och med ett musklick utför du exakt Och full söka efter länkar som innehåller specificerad information. Sökningen utförs på flera sökmotorer samtidigt, med alla detaljer på en gång, med flera möjliga kombinationer av inspelningsdetaljer samtidigt: kom ihåg hur du kan skriva ner ett telefonnummer på olika sätt. Efter en viss tid, utan att göra tråkigt rutinarbete, kommer du att få en lista med länkar, rensade från upprepningar och, viktigast av allt, sorterade efter relevans för objektet du letar efter. Relevans (signifikans) uppnås på grund av det faktum att den första i SiteSputniks sökresultat kommer att vara de länkar som mer uppgifterna du angav, och inte de som flyttade upp sökmotorns resultat för den webbansvariga.
Viktig .
SiteSputnik-programmet är bättre än andra program på att extrahera verklig, inte officiell information om objektet. Till exempel i den officiella databasen mobiloperatör det kan registreras att telefonen tillhör Vasily Terekhin, men i verkligheten innehåller den här telefonen information om att Alexander sålde en Ford Focus-bil 2013, vilket är ytterligare information att överväga.Sökövervakning .
Sökövervakning innebär följande. Om du behöver spåra händelsen nya länkar, av ett givet objekt eller godtycklig paket med frågor, då behöver du bara periodvis upprepa sökningen som motsvarar det. Samma som för en enkel begäran, programmet SiteSputnik kommer att skapa en "Ny" lista, som endast kommer att inkludera de länkar som inte hittades i någon av de tidigare sökningarna.Sökövervakning intressant inte bara i sig. Det kan vara inblandat i övervakning av media, sociala nätverk och andra nyhetskällor, som nämndes ovan i punkt 1. Till skillnad från andra program, där det är möjligt att få ny information endast från RSS-flöden, i programmet WebbplatsSputnik kan användas för detta sökningar inbyggda i webbplatser Och sökmotorer . Också möjligt tävlan(självskapande) flera RSS-flöden från godtyckliga sidor, dessutom emulering av ett RSS-flöde på begäran och till och med en grupp förfrågningar.
- För att få ut det mesta av programmet, använd dess huvudfunktioner, nämligen:
- begär paket, paket med parametrar, använd Assembler (assembler), operationen "Analytisk sammanslagning" av resultaten från flera jobb, om nödvändigt, tillämpa grundläggande sökfunktioner på det osynliga Internet;
- koppla dina källor till de informationskällor som är inbyggda i programmet : andra sökmotorer och sökningar inbyggda i webbplatser, befintliga RSS-flöden skapade av dig egna RSS-flöden Med godtycklig sidor, använd sökfunktionen för nya källor;
- använda följande typer av funktioner övervakning: Media, sociala nätverk och andra källor, övervakning kommentarer för nyheter och meddelanden, spåra utseendet på ny information på befintliga sidor;
- engagera Kategorier , Externa funktioner, Schemaläggare, e-postlista, flera datorer, Projektinstruktör, installera larm För att meddela dig om händelsen av betydande händelser, använd de andra funktionerna nedan.
- Program SiteSputnik förbättras ständigt inom följande områden: "Jag måste hitta allt och med garanti".
"Frågeprogram för Internet", - en annan definition av Användaren för att tilldela programmet.A. Funktioner för att söka och samla in information.
. Begär paket - utförande av flera frågor samtidigt, kombinera sökresultat eller separat. När det kombinerade resultatet genereras tas länkar som hittas upprepade gånger bort. Mer information om paket finns i introduktionen till SiteSputnik och visuellt i videon: gemensam Och separat verkställande av förfrågningar. Det finns inga analoger i inhemsk och utländsk utveckling.
. Paket med parametrar. Alla frågor och frågepaket utformade för att lösa vanliga sökuppgifter, till exempel sök efter telefonnummer, fullständigt namn eller e-post, - kan parametriseras, sparas och exekveras från ett bibliotek av färdiga frågor med ersättning av faktiska (nödvändiga) parametervärden. Varje paket med parametrar är sin egen specialitet avancerat sökformulär . Den kan använda inte en utan flera sökmotorer. Du kan skapa formulär som är mycket komplexa i sitt funktionella syfte. Det är oerhört viktigt att formulär kan skapas av användarna själva, utan deltagande av programförfattaren eller programmeraren. Detta är mycket enkelt skrivet i instruktionerna, mer detaljer i en separat publikation om sökparameterisering och på forumet, tydligt i videon: sök efter alla alternativ för att spela in ett nummer på en gång mobiltelefon och enligt flera alternativ för att registrera adressen e-post. Det finns inga analoger.
. Assemblerare NY- sammanställa en sökuppgift från flera färdiga sådana : förfrågningar, förfrågningspaket och parameterpaket. Paketen kan innehålla andra paket i sin text. Kapslingsdjupet för paket är obegränsat. Du kan skapa flera sökuppgifter, till exempel om flera juridiska och individer, och slutför dessa uppgifter samtidigt. Mer information på forumet och i en separat publikation om Assembler, tydligt på video. Det finns inga analoger.
. Metasök - exekvering av en specifik begäran samtidigt på ett givet "djup" av sökningen för var och en av dem. Metasearch är möjligt med hjälp av inbyggda sökmotorer, som inkluderar Yandex, Rambler, Google, Yahoo, MSN (Bing), Mail, Yandex och Google-bloggar och anslutna sökverktyg. Att arbeta med flera sökmotorer ser ut som att du arbetar med en sökmotor . Återhittade länkar raderas. Visuellt metasök på tre anslutna sociala nätverk: VKontakte, Twitter och Youtube - visas på video.
. Metasök på sajten - kombinera webbplatssökning i Google, Yahoo, Yandex, MSN (Bing). Klart på video.
. Metasökning i kontorsdokument - kombinera sökning i filer PDF-format, XLS, DOC, RTF, PPT, FLASH i Google, Yahoo, Yandex, MSN (Bing). Du kan välja vilken kombination av filformat som helst.
. Metasök efter cache-kopior länkar i Yandex, Google, Yahoo, MSN (Bing). En lista sammanställs, vars varje objekt innehåller alla utdrag som hittas för varje länk av varje sökmotor. Det finns inga analoger.
. Deep Search för Yandex, Google och Rambler låter dig kombinera till en lista alla länkar från den vanliga sökningen respektive alla länkar från listorna "Mer från webbplatsen", "Ytterligare resultat från webbplatsen" och "Sök på webbplatsen (Totalt) ...)”. Läs mer om djupsökning på forumet. Det finns inga analoger.
. Noggrann och fullständig sökning . Det betyder följande. Å ena sidan kan varje fråga exekveras på det och endast på den källa på vars frågespråk den är skriven. Detta exakt sökning. Å andra sidan kan det finnas ett godtyckligt antal sådana förfrågningar och källor. Detta ger fullständig sökning. Läs mer i ett separat inlägg om procedursökning. Det finns inga analoger.
. Söker på det osynliga internet .
Den innehåller följande grundläggande funktioner:
B. Informationsövervakningsfunktioner.Ett speciellt paket med förfrågningar som kan förbättras av användaren,
- sök efter osynliga länkar med en spindel,
- sök efter osynliga länkar i närheten av en synlig länk eller mapp med "bild och likhet",
- speciella sökningar efter öppna mappar,
- sök efter osynliga länkar och mappar med standardnamn med hjälp av speciella ordböcker,
- användning av dina egna sökningar inbyggda i webbplatser.Mer information i en separat publikation på SiteSputnik Invisible. De grundläggande funktionerna är "välkända i snäva kretsar", men sättet de används på har inga analoger. Kärnan i denna metod är att bygga en webbplatskarta som är synlig från Internet (med andra ord materialiseras synligt internet), och endast på basis av synliga länkar och sök efter osynliga länkar i relation till dem. Sökning efter redan synliga länkar med "osynliga" metoder utförs inte.
. Övervakning för framträdande på Internet ny länkar om ett visst ämne. Övervaka utseendet ny länkar kan användas med heltal begära paket , som involverar någon av sökmetoderna som nämns ovan, snarare än enskilda sökmotors förstasidor. Genomfört förbund och korsning ny länkar från flera separata sökningar. Mer information finns i publikationen om övervakning (se § 1) och på forumet. Det finns inga analoger.
. Kollektiv informationsbehandling . Skapelse företags- eller professionellt nätverk för kollektiv insamling, övervakning och analys av information. Deltagarna och skaparna av ett sådant nätverk är anställda i företaget, medlemmar av en professionell gemenskap eller intressegrupper. Det geografiska läget för deltagarna spelar ingen roll. Mer information i en separat publikation om att organisera ett nätverk för kollektiv insamling, övervakning och analys av information.
. Övervakning länkar (webbsidor) för att upptäcka ändringar i deras innehåll (innehåll). Betaversion. Hittade ändringar markeras med färg och specialsymboler. Mer detaljer i en separat publikation om övervakning (se 2 och 3 §).
I. Informationsanalysfunktioner.
. Kategorier av material redan beskrivits ovan. Mer information finns i en separat publikation om Rubrics. Regler för att ange rubriker låter dig ange nyckelord och avståndet mellan dem, ställa in logiska "AND", "ELLER" och "NOT", tillämpa en parentesstruktur på flera nivåer och ordlistor (infoga filer) som du kan använda på logiska operationer.
. VF-teknik - en nästan godtycklig utökning av möjligheten att kategorisera material genom implementering av externa funktioner som är organiskt integrerade i reglerna för inmatning av rubriker och kan implementeras av programmeraren självständigt utan medverkan av programförfattaren.
. Numerisk analys inflyttning av Rubriks, installation larm och meddelande om förekomsten av betydande händelser genom att markera rubrikerna i färg och/eller skicka en larmrapport via e-post.
. Saklig relevans. Det finns en möjlighet att ordna länkarna i ordning nära betydelse dessa länkar i förhållande till problemet som ska lösas, förbi tricks av webbansvariga som använder olika sättöka webbplatsrankingen i sökmotorer. Detta uppnås genom att analysera resultaten av att utföra flera "mångfaldiga" frågor om ett givet ämne. I ordets bokstavliga bemärkelse, länkar som innehåller maximal information som krävs . Läs mer i beskrivningen av hur du hittar den optimala leverantören och på forumet. Det finns inga analoger.
. Beräkna objektrelationer - söka efter länkar, resurser (sajter), mappar och domäner där objekt nämns samtidigt. De vanligaste föremålen är människor och företag. För att söka efter anslutningar kan alla programverktyg som nämns på denna sida användas SiteSputnik, vilket avsevärt ökar effektiviteten i det arbete du utför. Operationen utförs på valfritt antal objekt. Mer detaljer i introduktionen till programmet, samt i beskrivningen ny funktion"objekt och deras kopplingar." Det finns inga analoger.
. Bildande, integration och korsning av informationsflöden om en mängd olika ämnen, jämförelse av trådar. Mer detaljer i ett separat inlägg på trådar.
. Bygga webbkartor webbplatser, resurser, mappar och genomsökta objekt baserat på de som finns på Internet när Google hjälp, Yahoo, Yandex, MSN (Bing) och Altavista länkar som hör till webbplatsen. Experter kan ta reda på: är det synligt "extra" information från Internet på deras webbplatser, såväl som undersökningskonkurrenters webbplatser om detta ämne. Webbplatskarta är materialisering av det synliga internet . Mer information i en separat publikation om att bygga webbkartor, visuellt på video. Det finns inga analoger.
. Att hitta nya informationskällor om ett givet ämne, som sedan kan användas för att spåra uppkomsten av ett nytt nödvändig information. Mer information på.
G. Servicefunktioner.
. Uppgiftsschemaläggare ger arbete enligt schema: utför specificerade programfunktioner vid en given tidpunkt. Mer information i en separat publikation om Planeraren.
. Projektinstruktör NY- det här är en assistent skapande och underhåll Projekt för att söka, samla in, övervaka och analysera information (kategorisering och signalering). Mer information på forumet.
. Automatisk arkivering. I databaser Alla resultat av ditt arbete kommer automatiskt ihåg, nämligen: förfrågningar, förfrågningspaket, sök- och övervakningsprotokoll, någon annan av ovanstående funktioner och resultaten av deras exekvering. Burk strukturera arbeta med ämnen och underämnen.
. Databas inkluderar sortering, enkel sökning och anpassad sökning med SQL-fråga. För det senare finns en guide för att skapa SQL-frågor. Med hjälp av dessa verktyg kan du hitta och granska det arbete du gjorde igår, förra månaden, för ett år sedan, definiera ett ämne som ett sökkriterium eller ställa in ett annat sökkriterium baserat på innehållet i databasen.
. Tekniska begränsningar sökmotorer. Vissa begränsningar, som längden på frågesträngen, kan övervinnas. Det säkerställer att inte en, utan flera sökfrågor utförs, kombinerade sökresultat eller separat. Du kan läsa om ett sätt att övervinna brott mot lagen om additivitet för stora sökmotorer. För ett ord eller en fras inom citattecken genomförs en skiftlägeskänslig sökning i sökmotorer, i synnerhet sökning med förkortningar.
Inbyggt webbläsare . Navigatör per sida. Flerfärgad markör för att markera nyckelord och godtyckliga ord. Bilisting och N-listning från genererade dokument.
. Avlastning nyhetsflöden in i en tabellvy fokuserad på importera i Excel, MySQL, Access, Kronos och andra applikationer.
För att installera och köra programmet:
- Ladda ner filen, kopiera mappen FileForFiles från den till din hårddisk till exempel på D:\;
- Demoversion av programmet kommer att installeras och den kommer att öppnas.
Programmet fungerar på alla datorer med vilken version av Windows som helst installerad.Prata om vad i vår tid informationsteknik och den oändliga tillväxten i mängden data som är tillgänglig för både en individ och samhället, det finns många problem med att bearbeta information och söka efter den - detta är redan hädelse. Vem tar inte upp detta ämne? Och för att inte belasta dig med subjektiva och delvis objektiva bedömningar hämtade från olika informationskällor angående problemet kommer jag att gå direkt till dess lösning. Idag ska vi prata om sökning. Det vill säga om program och seriösa informationssystem som söker efter de dokument och data vi behöver.
Uppgradera "direktsökning"
För inte så länge sedan, när träden var stora, och information även in lokalt nätverk det fanns inte så många företag, någon sökning utfördes genom en banal sökning av en handfull tillgängliga filer och en sekventiell kontroll av deras namn och innehåll. En sådan sökning kallas direkt, och program (verktyg) som använder direktsökningsteknik finns traditionellt i alla operativsystem och verktygspaket. Men även kraften moderna datorer inte tillräckligt för snabb och adekvat sökning i gigantiska datamängder vid direktsökning. Att söka igenom ett par hundra dokument på en disk och söka i ett enormt bibliotek och flera dussin brevlådor är två olika saker. Därför bleknar direktsökningsprogram idag tydligt i bakgrunden - om vi pratar om om universella medel.
Naturligtvis har denna typ av sökning inte efterfrågats på länge inom företagssektorn. Volymerna är inte desamma. Och därför är tekniker som snabbt och exakt kan söka efter dokument i olika format och från olika källor mer än relevanta i många år nu, och nyligen helt klart. För inte så länge sedan tillkännagav Microsofts "far" Bill Gates, uppenbarligen avundsjuk på den fenomenala framgången för internetsökmotorn Google, vid en av presskonferenserna mjukvaruindustrins (och inte bara) önskan att bidra på alla möjliga sätt, utveckla och fördjupa skapandet av sökmotorer och tekniker. Men det är för tidigt att skapa något fenomenalt fungerande program från Microsoft eller en konkurrerande server på Internet (MSN når fortfarande inte Google). Låt oss därför vända oss till befintlig utveckling. Index, fråga, relevans
Modern teknik bygger på två grundläggande processer. Först och främst är det indexering. tillgänglig information och bearbeta begäran och sedan mata ut resultaten. När det gäller det första, vilket program som helst (vare sig det är en sökmotor för stationära datorer, företag informationssystem eller Internetsökmotor) skapar sitt eget sökområde. Det vill säga att den bearbetar dokument och genererar ett index över dessa dokument (en organiserad struktur som innehåller information om de behandlade uppgifterna). I framtiden är det det skapade indexet som används för arbete - snabbt få en lista över nödvändiga dokument enligt begäran. Vad som följer, även om det inte på något sätt är enkelt tekniskt sett, är ganska förståeligt till den genomsnittliga användaren. Programmet behandlar begäran (med hjälp av en nyckelordsfras) och visar en lista över dokument som innehåller denna nyckelordsfras. Eftersom informationen finns i ett strukturerat index, är frågebehandlingen mycket snabbare (tiotals och hundratals gånger!) än vid direktsökning (dokument väljs inte genom att söka igenom filer, utan genom att analysera textinformation i indexet).
Programmet visar de hittade dokumenten i den resulterande listan efter relevans - dokumentets överensstämmelse med frågetexten. I olika tekniker finns det naturligtvis olika metoder för att söka och bestämma relevansen av ett dokument (antalet "förekomster" av ett ord och dess omnämningsfrekvens i dokumentet, förhållandet mellan dessa parametrar och det totala antalet ord i dokumentet, avståndet mellan orden i frågefrasen i de sökta filerna och så vidare). Baserat på dessa parametrar bestäms dokumentets "vikt" och beroende på den visas en viss fil i resultatlistan på en viss position. När det gäller internetsökning är situationen ännu mer komplicerad. När allt kommer omkring, in i detta fall många andra faktorer måste beaktas (Googles Page Rank är ett exempel på detta). Men det här är ett ämne för en separat artikel, så vi kommer inte att röra Internet Granskning av sökmotorer
Detta material undersöker kapaciteten hos flera populära sökprogram som kan skryta med både anständiga hastigheter och bra funktionalitet. Men att visa upp sig i broschyrer är en sak, men att stå under en experts blick är en helt annan. Och det fanns inga fler experter, inte mindre ett kontor fullt av människor som gillade att mixtra med programvaran för dess användbarhet. På en experimentell dator (Athlon 2,2 MHz, med en kapacitet RAM 1 GB, 160 GB IDE hårddisk Seagate vid 7200 rpm och Windows-system XP) installerades en uppsättning program: dtSearch Desktop, Bloodhound Prof Deluxe, Google Desktop Search, SearchInform, Copernic Desktop Search, ISYS Desktop. För testerna sammanställdes en textdatabas med dokument i doc-, txt- och html-format med en total storlek på varken mer eller mindre, utan 20 gigabyte. En grupp kamrater under ledning av din ödmjuka tjänare testade, jämförde och delade sina subjektiva intryck av varje programvara. Läs en sammanfattning av resultaten nedan. dtSearch Desktop
Ett program som, enligt utvecklarna, säger sig vara den snabbaste, bekvämaste och bästa sökmotorn. Som i allmänhet alla andra från denna recension. Gränssnittet för dtSearch är ganska enkelt, men vissa fönster eller flikar är något överbelastade med element, vilket gör att det verkar svårt att använda. Men i verkligheten finns det inga särskilda svårigheter. Den enda riktigt obehagliga punkten är programvarans brist på stöd för det ryska språket (trots att programmet kan söka efter dokument på flera språk är dess gränssnitt uteslutande engelska).
Men dtSearch är ett av få program som kan indexera webbsidor till ett användarspecificerat "djup" (om än med hänsyn till "extra köp" av dtSearch Spider-tilläggssatsen). Detta är förutom att stödja filer på disk av olika textformat och e-postmeddelanden från brevlåda Syn. Samtidigt kan programmet inte fungera med databaser, som är en så välsmakande bit för sökmotorer på grund av de stora mängderna information som finns i dem och deras breda spridning i företag, och därför i företagsnätverk. Hastigheten för att indexera dtSearch-dokument visade sig vara på rätt nivå. Framöver kommer jag att säga att det här programmet klarade indexeringen av en given mängd information på nivå med en annan konkurrent - iSYS - och delade andraplatsen med den i listan över de snabbaste systemen. dtSearch indexerade ett test på 20 gigabyte information på 6 timmar och 13 minuter, vilket skapade ett index på 7,9 GB för efterföljande sökbehov.
När det gäller sökfunktionerna, här är de på rätt nivå. För det första har dtSearch en morfologisk sökning (sökning efter ett ord i alla dess morfologiska former). Använder denna möjlighet, frigör du dig från, säg, sådana tankar som "i vilket fall användes ett visst ord i dokumentet jag behövde?" Användningen av morfologisk sökning är nästan alltid motiverad, så den bör finnas i alla professionella sökmotorer.
Sök efter ljud är en icke-standardfunktion även för professionella sökmotorer. Dess kärna är att programmet kommer att söka efter ord som låter likadant som det ord du skrev in. Och det bästa är att den här funktionen också fungerar för det ryska språket! När du till exempel skriver ordet "öra" i en sökfråga ser du inte bara orden "öra" utan också "öra" som ett resultat.
Sökning med felkorrigering är en mycket viktig funktion. Det används för att söka efter ord som innehåller syntaktiska fel - dessa kan vara antingen stavfel eller fel i dokument som erhållits med hjälp av teckenigenkänningssystem, till exempel. Ett enkelt exempel - du letar efter ordet tangentbord. Vissa dokument innehåller ordet "tangentbord", det är uppenbart att detta faktiskt är ordet "tangentbord", personen gjorde precis ett stavfel när han skrev. Så en felkorrigeringssökning kommer att upptäcka och inkludera ett dokument med ordet "tangentbord" i resultatet. Det finns också en inställning i dtSearch som låter dig bestämma graden av möjliga felaktiga tecken.
Sök med synonymer. Den här funktionen använder en lista med synonymer för olika ord. Så, till exempel, genom att ange ordet "snabb", kommer programmet också att hitta orden "höghastighet" och andra som är synonymer för ordet "snabb", om de, naturligtvis, finns i listan över synonymer . En färdig lista med synonymer medföljer inte dtSearch-programmet, men det är möjligt att använda listor på Internet (därför krävs en anslutning, vilket inte alltid är bekvämt), eller så kan du skapa din egen lista med synonymer .
Utöver de listade funktionerna kan dtSearch söka med fraser som består av ord kopplade med logiska operationer. Varje ord i en fråga kan tilldelas sin egen "vikt", det vill säga betydelse. Ett användbart alternativ är att använda en ordbok som består av oviktiga ord för att inte ta hänsyn till dem vid sökning, men även denna ordbok är tom och du måste fylla i den själv.
Låt oss sedan titta på programmets möjligheter när du arbetar på nätverket. Faktum är att dtSearch inte erbjuder några specifika funktioner för att arbeta med nätverket. Det är dock fullt möjligt att använda det online. Alternativt kan du skapa något slags index och lägga det i en offentlig (delad) mapp. Själva programmet kan installeras på varje användares dator, eller det kan också placeras i en mapp som är öppen för allmänheten, och genvägar kan skapas på ett speciellt sätt för varje användare separat, med hjälp av parametrarna kommandoraden, vars syfte beskrivs i hjälpfilen som medföljer programmet. Det finns också en möjlighet automatisk installation program till nätverket med hjälp av en MSI-fil. Detta kommer att ta hänsyn till inställningarna för varje ansluten användare.
Generellt sett är det ett bra program från kategorin professionella sökmotorer. Kan kvalificera sig för bra betyg, men att få förtroende och respekt från användare kanske inte är lätt för dtSearch på grund av vissa faktorer (allt är inte smidigt med gränssnittet, ryska användare är berövade, det finns inga ljusa funktioner för att arbeta med nätverket). När det gäller att direkt söka efter dokument hade programmet inga problem med rysk text. Eftersom det inte fanns några med den deklarerade morfologin, eller med en luddig sökning. Systemet hittade på ett bra sätt de nödvändiga dokumenten både genom en enkel fråga på ett ord och genom att använda ett par stycken eller ett dokument som nyckelfras.
Officiell webbplats:
Distributionsstorlek: 23 Mb Bloodhound Prof DeluxeBaserat på namnet kan du gissa att det finns stöd för det ryska språket i det här programmet. Det här är redan trevligt. När det gäller gränssnittet är det i allmänhet något ovanligt, men till utseendet är det väldigt attraktivt. En annan sak är bekvämlighet. Ett mycket kontroversiellt kriterium, men förmodligen är en lösning med flera fönster inte det mest framgångsrika alternativet (förfrågan skrivs in i ett fönster, resultatet visas i ett annat och liknande).
Snoop använder samma index för att utföra en snabb sökning, men indexeringen är mycket långsammare än andra program. Detta är mycket märkligt, särskilt med tanke på att dess förmåga att bearbeta sökfrågor är mycket svag, och därför är indexstrukturen inte komplex. Troligtvis beror detta på ooptimerade algoritmer. Detta program visade sig vara en tydlig outsider i indexering och sökhastigheter: tiden som läggs på att skapa ett index är sex gånger längre än för dtSearch och iSYS. Indexering av 20 gigabyte texter för blodhunden resulterade i 38 timmar och 46 minuters arbete. Och det skapade "sökområdet" tog upp samma storlek på hårddisken som originaldata med ett litet minus - 19 gigabyte.
Bloodhound kan presenteras som ett alternativ standardsökning i Windows kan den knappast mer. Det faktum att Snoopers primära uppgift är den enklaste sökningen efter filer indikeras inte bara av det lilla antalet funktioner för att analysera texten i sökfrågor och en avancerad sökning efter filattribut, utan även av ett resultatfönster som ger direktlänkar till hittade filer, samt till mapparna som innehåller dessa filer. Resultatfönstret är inte särskilt informativt i den meningen att du bara kan läsa hela den hittade filen genom att köra den, det vill säga att den inte har en inbyggd filvisare. Men ett utdrag ur filen där det sökta ordet hittades visas i allmänhet, detta visningsschema påminner mycket om sökmotorer på Internet.
På tal om specifika möjligheter för att bearbeta sökfrågor, är det värt att notera att det inte finns något sådant som "söktext" det maximala som kan sökas är en fras, om så bara för att det inte finns något textinmatningsfält med flera rader. Men du kan också analysera den inmatade frasen, och Snoop erbjuder oss en standard här: sökuppsättning: logiska operationer, masksökning och citatsökning... inte mycket. Programmet innehåller några rudiment av morfologisk sökning, men det är förmodligen så grovt att det med största sannolikhet stör korrekt funktion (under tester har många buggar med felaktig användning av morfologi märkts).
Men programmet låter dig ange filattribut när du söker (dokumentdatum, filnamn, mappnamn), och i dessa frågor kan du också använda samma sökuppsättning. Du kan också söka efter bokstäver genom att ange parametrarna (Från, Ämne..., etc.).
Så vi kom på själva sökningen, vad mer är intressant med programmet, som det fick så många utmärkelser för, enligt information från den officiella webbplatsen? Det är svårt att säga vad som är så speciellt med det, troligen är Bloodhound-gränssnittet attraktivt (exakt till utseendet, för att inte tala om användbarhet).
Operationer med index är mycket standard en trevlig funktion är möjligheten att uppdatera index på ett schema. Dessutom kan index också användas online. Från och med nu behöver vi mer detaljer.
Trots sökfrågornas primitivitet kan programmet användas för att söka efter filer, så dess användning kan motiveras i nätverk. Fast med stor sträckning, eftersom i ett stort nätverk är den prioriterade uppgiften snabb sökning data med hjälp av komplexa sökfrågor på grund av den enorma mängden information - och det finns helt klart problem med sökningens och programmets hastighet. Jag måste säga att arbetet med nätverket på Izhishika är genomtänkt som det ska. Designad speciellt för detta separat ansökan- Bloodhound Server. Det fungerar på samma sätt som helt enkelt Snooper (de har samma sökmotor), bara för dokument som finns på en central server eller på delade resurser i företagsnätverk. Snooper Server skapar nya index på delade resurser eller använder tidigare skapade. Alla användare av företagets nätverk kan ansluta till sökservern och använda den för att komma åt vilket dokument som helst (finns i det aktuella indexet) med en webbläsare. Håller med, detta schema är extremt bekvämt: det visar sig att filer på ditt eget nätverk kan sökas på samma sätt som information på Internet genom till exempel Google.
När man bedömer alla fördelar och nackdelar med detta program, tyder slutsatsen på att dess kapacitet sannolikt inte räcker för företagsnätverk (trots den goda organisationen av att arbeta med nätverket), utan för en hemdator eller till och med för hemnätverk I princip kan det vara lämpligt. Även om varken arbetshastigheten eller sökmöjligheterna inspirerar till optimism...
Officiell webbplats på ryska:
Distributionsstorlek: 6 MbGoogle Desktop Search + GDS EnterpriseNaturligtvis kunde vi inte ignorera en så berömd utvecklare. Namnet Google säger redan en hel del. Människor som har använt den mest kraftfulla sökmotorn på Internet i flera år kommer säkerligen, utan ett enda tvivel, att besluta sig för att installera just denna sökmotor på sin dator. Tänk bara: Googla på din hemdator! Men utan att ge efter för provokationer med ett brett marknadsfört varumärke, låt oss försöka nyktert, och viktigast av allt objektivt, att överväga kapaciteten hos "desktop"-sökmotorn från Google.
Det första som fångar ditt öga är avsaknaden av ett eget skal för programmet. Google Desktop Search finns fortfarande i webbläsarfönstret, respektive, hela gränssnittet för skrivbordsversionen ärvdes från programvaran från sin äldre Internetbror. Om detta är bra eller dåligt är en omtvistad fråga: vissa människor gillar minimalismen i designen av denna sökmotor, medan andra vill se en fullfjädrad applikation fylld med alla typer av knappar och så vidare.
Vad fångar dig direkt efter designen? Och det faktum att samma Google Desktop Search börjar indexera allt på datorn, utan någon efterfrågan! Och det som är mest intressant är att det är omöjligt att välja indexeringsvägar med Google Desktop Search. Du måste ladda ner ett separat program (TweakGDS), som gör att du kan expandera något Google-inställningar Desktop, inklusive ange de platser som krävs för indexering. Även om den redan kommer att indexera en standardhårddisk när du räknar ut allt detta, så det är mer sannolikt att den här inställningen behövs när du arbetar med stora mängder data, vilket är mycket viktigt när det används i företagsnätverk (Enterprise-versioner) . Det är dock inte ett faktum att efter att ha laddat ner TweakGDS kommer dina problem att lösas. Hon behöver trots allt Microsoft för att fungera. NET Framework och Microsoft Scripting Runtime. Ja... installationen, liksom åtkomsten till inställningarna, kunde ha gjorts enklare, även om utvecklarna säkert kan förstå: varför skriva något nytt när det finns en färdig sökmotor, portade det till den lokala datorn och låt användaren "njuter", och ett känt namn kommer att göra ännu ett mästerverk av "detta". Kom igen, låt oss avsluta denna lyriska utvikning och gå vidare till sökandet.
När det gäller att analysera sökfrågor och leverera resultat är allt här helt identiskt med Google på Internet: samma system för att visa resultat, samma standarduppsättning logiska operationer för sökfrågor. I allmänhet är Google Desktop Search, precis som det tidigare programmet, endast utformat för att söka efter filer - det har naturligtvis inte en intern visningsprogram för dessa filer. Antalet filformat som stöds av Google Desktop Search är ganska tillräckligt, och det är också trevligt att den söker på besökta internetsidor och tar data från cachen. Sök- och indexeringshastigheter är ganska acceptabla. Sant, för hemmabruk. Med imponerande 20 gigabyte Google texter Desktop Search slutförde uppgiften på 8 timmar och 17 minuter. Att spendera flera dagar på att bearbeta information från ett stort företags företagsnätverk är inget någon systemadministratör skulle vilja göra. På plussidan: storleken på det skapade indexet var på samma nivå (4,5 GB) som en annan sökmotor som testades i denna recension - SearchInform.
Den stora fördelen (eller nackdelen – du bestämmer själv) med Google Desktop Search är att den stöder plugins, vilket kan förändra mycket till det bättre. En annan sak är att att ansluta plugins och ställa in dem komplicerar uppgiften att installera en sökmotor så mycket att du börjar undra om allt detta är nödvändigt när du kan installera ett normalt, fullfjädrat program där allt redan kommer att finnas. När allt kommer omkring, för att använda varje funktion måste du installera nytt plugin. Även för att programmet ska fungera fullt ut med arkiv behövs en separat pryl. Det är fascinerande och förföriskt att alla dessa extra moduler är gratis. Men om du inte tar hänsyn till skrivbordsversionen av sökmotorn, kan det hända att en kompetent konfiguration av GDS Enterprise inte ligger inom din makt - trots allt är det inte för inte som specialister från Google erbjuder sina tjänster för att sätta upp sina egna programvara för ditt nätverk för endast $10 000.
Om du går igenom installations- och installationsproceduren (eller betalar 10 000 USD till ett team för snabba svar från Google), kommer du att förstå att komplexiteten i installationen mer än kompenseras av de mycket flexibla inställningarna när de används i företagsnätverk. En viktig punkt Google arbete Desktop på ett företagsnätverk är att använda grupppolicyer, vilket gör det möjligt att göra inställningar för varje användare.
För att sammanfatta, den mest rimliga användningen av detta program är en hem- eller arbetsdator. När allt kommer omkring för vanlig dator Du behöver bara installera programmet - det kommer att göra resten själv (det kommer inte ens att fråga dig något).
Google Desktop Search Enterprise kommer dock att vara acceptabelt i fall där det finns ett akut behov av flexibel konfiguration av nätverkspolicy för att använda sökmotorn, medan förmågan att bearbeta sökfrågor kommer att vara på andra plats i betydelse, och tiden (eller pengarna) ) som spenderas på att sätta upp programmet kommer att hamna på första plats.
Officiell webbplats:
Distributionsstorlek inklusive TweakGDS: 1,2 MbCopernic Desktop SearchKlicka på bilden för att förstora
Programgränssnittet väcker extremt positiva känslor - allt görs i enlighet med allmänt accepterade standarder, inget överflödigt, med ett ord, en trevlig design. För en nybörjare är det mycket enkelt att förstå Copernic Desktop Search-gränssnittet. Även om det är något förvirrande att designers tydligt skapade programgränssnittet med hänsyn till det faktum att programmet kommer att fungera i standardtema Windows XP design. När man använder det klassiska temat ser programmet inte så snyggt ut. Men det här är mer en smaksak.
Vid den första lanseringen uppmanar programmet dig att skapa index för sökning. Det verkade något ovanligt att efter att ha valt mappar för indexering, erbjöd programmet inte att trycka på någon knapp, till exempel "Starta indexering", och indexeringen startade inte automatiskt, först då märktes det att Copernic försökte börja indexera medan datorn var ledig. Du måste gräva lite djupare i programmets alternativ för att konfigurera allt korrekt. Det bör noteras att det finns ganska breda anpassningsalternativ här. automatiskt skapande index: inbyggd schemaläggare, möjligheten att indexera när datorn är inaktiv, i bakgrunden, med låg prioritet. Indexeringen gick inte för snabbt - 10 timmar 51 minuter - detta är långsammare än i andra sökmotorer (förutom Isle of Bloodhound, men Copernic är fortfarande en storleksordning snabbare än utvecklingen av iSleuthHound Technologies.
Nu om indexets struktur. I allmänhet är det inget speciellt med det. Det är möjligt att välja filtyper, både i allmän och detaljerad form. Det vill säga att du initialt kan välja vad du vill indexera - Dokument, Bilder, Videor, Musik. På den andra fliken i alternativfönstret kommer du att kunna välja specifika filtyper efter förlängning. Dessutom kan du konfigurera indexet så att till exempel bilder som är mindre än 16x16 i storlek inte indexeras eller ljudfiler som är kortare än 10 sekunder inte indexeras. Förutom att indexera filer från mappar kan Copernic arbeta med e-postmeddelanden och kontakter från adressboken Microsoft Outlook och Microsoft Outlook Express, indexering av favoriter och historik från Internet Explorer är möjlig.
När det gäller sökmöjligheterna är de väldigt svaga här. Under tester avslöjades det till och med att programmet inte söker efter dokument i txt- och html-format på ryska, vilket gör att du bara kan hitta dem efter titlar och inte efter innehåll. Det enda programmet tillhandahåller för att förbättra sökeffektiviteten är att använda standarduppsättning logiska operationer, och även då upptäcktes denna möjlighet experimentellt, eftersom den inte var dokumenterad. Förresten, inte allt är i sin ordning med programmets hjälp heller - det är bara tillgängligt via Internet, vilket, du ser, är väldigt obekvämt, och till och med på Internet referensinformation inte för mycket. Tydligen bestämde utvecklarna att programmets enkla gränssnitt inte innebär närvaron av normal hjälp. För att fortsätta samtalet om sökfunktioner bör det noteras att programmet, trots den svaga analysen av frågor, erbjuder ett intressant söksystem - användaren kan välja typ av filer (bilder, videor, musik etc.), ange en sökning fråga och välj attribut som är specifika för den valda filtypen. Till exempel, för ljudfiler kan dessa vara värden från mp3-taggar (artist, album, datum, etc.), för bilder kan du till exempel välja storlek (efter upplösning), i allmänhet har varje typ sin egna inställningar. Efter att ha sökt efter en specifik filtyp kommer programmet att visa en mycket informativ lista i resultatfönstret, och om din förfrågan innehåller filer av andra typer kan du öppna dem genom att klicka på en specifik länk.
Separat är det värt att nämna resultatfönstret. Under listan över hittade filer visas innehållet i dessa filer (ett liknande schema används ofta i e-postklienter). Det är sant att textvisning endast kan göras i det ursprungliga formatet, och det finns inget visningsläge för vanlig text, vilket inte alltid är bekvämt, eftersom att öppna ett dokument i det här fallet tar mer tid. Men med tanke på att Copernic kan söka efter bilder och musik är det möjligt att se dessa multimediafiler.
De grundläggande principerna för driften av detta program beskrivs, nu ska vi se vad Copernic Desktop Search kan erbjuda oss för att arbeta med nätverket... I princip kan du titta väldigt länge, men du kommer knappast att kunna se något . Det här programmet var med andra ord inte tänkt att vara nätverksbaserat. Copernic Desktop Search är enbart en sökmotor för hemmet.
Uppenbarligen är den enda (mest logiska) tillämpningen av detta program hemdator. Här kommer den helt att klara alla enkla användarsökningsfrågor som består av ett eller två ord, hittar den nödvändiga informationen och uppdelningen av sökningen efter filtyp och stöd för multimediafiler tillsammans med bakgrundsindexering i lågprioritetsläge, tillsammans med en trevlig gränssnitt, ge bara programmet styrka att vinna förtroende bland oerfarna användare.
Officiell webbplats
Distributionsstorlek: 2,6 MbISYS DesktopKlicka på bilden för att förstora
Ett mycket kraftfullt program. När det gäller dess utrustningsnivå med alla möjliga funktioner ligger den någonstans nära nästa SearchInform söksystem på listan. Dessutom är storleken på installationsfilen mer än 40Mb! Det är svårt att säga vad som skulle kunna pressas in i sådana dimensioner, eftersom samma SearchInform, med liknande funktionalitet, tar upp 15 Mb.
Installationsprocessen här är inte heller särskilt trevlig, eller snarare inte ens installationsprocessen. Redan innan du laddar ner programmet kommer du att bli ombedd att registrera dig, annars finns det ingen möjlighet. Därefter gränssnittet. Det är mycket snyggt gjort, inget onödigt fångar ögat, men det här är intrycken av en person som redan är lite van vid det. Det kommer inte att vara lätt för en nybörjare att ta reda på var och vad som finns, var man ska klicka och var man slutligen ska söka. Det rekommenderas starkt att läsa hjälpen innan du börjar arbeta - du kommer att spara mycket nerver och tid. Till allt annat är den totala bristen på stöd för det ryska språket i programmet. Dålig. Dessutom är fönstren här inte överbelastade med kontroller, utan vi fick betala för detta med multimoduler och användning av ytterligare fönster. Till exempel läggs sökfrågor in genom att starta ett program och indexhantering utförs med ett annat program. Sökfrågor läggs även in här i separata popup-fönster. Det är svårt att säga vilket som är bättre - ett överbelastat gränssnitt eller allestädes närvarande multi-fönster snarare, det är en smaksak.
När det gäller att skapa index, tillhandahåller programmet funktioner för att förenkla processen att ställa in alternativ för ett nytt index. Dessa funktioner inkluderar flera färdiga mallar att skapa index för mappen "Mina dokument", "Mail", "Mail och dokument", "Specific mapp", "Mapp med ett urval av filtyper" etc. Sådana mallar förenklar skapandet av index i det första steget. Verktyget för att arbeta med index har inte ett särskilt bra gränssnitt, vilket är skrämmande med viss komplexitet (detta är en väldigt subjektiv bedömning, för att vara ärlig), men om du tittar på det ger det många användbara alternativ och i allmänhet , dess användning orsakar inte mycket svårigheter. ISYS Desktop kan indexera data från olika datakällor och tillhandahåller även en mängd olika flexibla inställningar för sådan indexering. Bland ytterligare funktioner för indexering: stöd för SQL, FTP, TRIM Context, WORLDOX 2002, skript. När du skapar ett index, om du valt "Mapp med urval av filtyper" har du möjlighet att välja filtyper för indexering manuellt (i förlängning). Det måste sägas att det helt enkelt finns ett stort antal filtyper som stöds, men lägg till din egen typ (tillägg) till befintlig lista det kommer inte att fungera. Du kan också notera närvaron av en indexeringsschemaläggare. Att skapa ett index och bearbeta 20 gigabyte information tog ISYS Desktop 6 timmar och 13 minuter, vilket slutligen visade en bra tid och storleken på den skapade filen - 7,9 GB.
Sökmöjligheterna i detta program är ganska bra. Det som används i ISYS är mycket kraftfullare än konventionellt stöd för logiska operationer. Bland de avancerade sökmöjligheterna erbjuder programmet användning av synonymer och ett sorteringsfilter (efter sökväg, namn och datum för filskapandet). Uppsättningen av logiska operatorer är något bredare än standarduppsättningen. Förutom logiska operationer låter programmet dig arbeta med många andra operatorer, som i princip kan ersätta vissa typer av sökningar, till exempel kan sökning med parsning ersättas helt med hjälp av speciella operatorer. Jag blev mycket förvånad över att programmet inte har en sökning med hjälp av morfologi. Detta är en allvarlig försummelse, eftersom sökeffektiviteten förbättras avsevärt när man använder morfologisk analys. Dessutom finns det ingen lista över betydelsefulla ord, men det finns en omfattande lista över obetydliga ord. Sökfunktioner som "ungefärlig sökning" och "heuristisk analys" annonseras också.
ISYS erbjuder ett urval av flera typer av sökfrågor, nämligen visuella. Detta görs med olika typer av fönster för att ange sökfrågor, men i själva verket tillåter inte ett enda fönster användning av andra tekniker än de som anges ovan.
Sökresultaten är mycket informativa och visas som en lista över dokument sorterade efter relevans. En förhandsgranskning av det valda dokumentet visas nedan. Till skillnad från Copernic Desktop Search är förhandsgranskningen här endast tillgänglig i form av vanlig text. Det var inte möjligt att visa dokument i deras ursprungliga format, vare sig det är Word, Html eller PDF, även om detta i princip inte är alltför kritiskt. Programmet låter dig dela upp hittade dokument i grupper enligt vissa kriterier (som standard är de uppdelade efter relevans). Du kan också se redan hittade dokument genom att välja enskilda mappar (detta är praktiskt när resultatet ger ett mycket stort antal dokument).
Att använda programmet på ett företagsnätverk är också mycket motiverat, eftersom det ger goda möjligheter att organisera nätverkssökning. Söksystemet bygger på skapandet av ett offentligt index som innehåller indexerad data från allmänt tillgängliga onlineresurser.
Faktum är att programmet från ISYS är värt att uppmärksammas, åtminstone att bekanta sig med det. Det här programmet är ett moget projekt med ett stort antal funktioner (inte alltid och inte alla behöver naturligtvis dem, men ändå). Chansen att programmet kommer att se några förbättringar när det gäller bearbetning av sökfrågor är okända, men just nu den kan rekommenderas för nästan universell användning. Och med tanke på att det fortfarande är för tungt för hemsystem, är de viktigaste platserna för installationen företagsnätverk.
Officiell webbplats:
Distributionsstorlek: 40 MbSearchInformKlicka på bilden för att förstora
Det är förmodligen inte värt att börja direkt med en beskrivning av SearchInform-gränssnittet. Vi bör först beskriva installationsprocessen, eller snarare en av dess detaljer: du kan inte installera programmet utan en internetanslutning. Faktum är att innan den första lanseringen kräver programmet användarregistrering (gratis) och skickar all inmatad data till servern. Tydligen var utvecklarna tvungna att vidta sådana åtgärder i kampen mot piratkopiering, men detta hade inte en positiv effekt på installationens enkla.
Programgränssnittet är utformat i enlighet med alla allmänt accepterade regler, men vid första anblicken är det något besvärligt. När du använder programmet för första gången verkar det vara för komplicerat, ibland är det inte lätt att komma ihåg i vilken meny eller på vilken flik det önskade alternativet finns, men med längre användning verkar gränssnittet inte längre så fruktansvärt komplext . Det viktigaste är att läsa intyget först.
Efter att ha förstått gränssnittet lite kan du börja skapa ett index. Själva processen är väldigt enkel och indexeringshastigheten, även per öga, är betydligt högre än alla andra sökmotorer i recensionen. Tydliga testsiffror visar att SearchInform är dubbelt så snabb som dtSearch och iSYS vad gäller indexeringshastighet! Programmet indexerade den tillhandahållna datan i mängden 20 gigabyte på en rekordtid på 3 timmar och 17 minuter. Och storleken på det skapade indexet visade sig vara den minsta 4,4 GB - 100 megabyte mindre än Google Desktop Search.
Programmet stöder, förutom vanliga filer och mappar, även indexering av e-postmeddelanden, sammankoppling och indexering av databaser (!) och andra externa källor (DMS, CRM), direkt under indexeringen kan du ange en ordbok för att utföra en morfologisk sökning, och alla attribut kan vara indexerade filer. När du har skapat indexet, när du försöker göra den första testsökningen efter dokument, kan du bli något förvirrad: "det finns två typer av sökning här, men vilken behöver jag?" Som nämnts tidigare är det viktigaste att läsa hjälpen, då blir allt klart. Programmet kan faktiskt utföra två typer av sökningar - frassökning och sökning efter dokument som till innehåll liknar frågetexten.
En beskrivning av alla huvudfunktioner för att analysera en sökfråga gavs ovan, så nu kommer vi bara att lista sökmöjligheterna som tillhandahålls av detta program. Låt oss börja med frassökning: naturligtvis morfologisk sökning, citeringssökning, logiska operationer, sökning med ordanalys (sök i början av ordet, i slutet, i mitten eller en fullständig matchning), blandad citeringssökning ( när alla ord från frågan måste finnas i dokumentet, men inte nödvändigtvis i den angivna ordningen), sök med felkorrigering, användning av synonymer, "nästan citatsökning" (sök på den inmatade frasen som citat, men andra ord kan ev. vara närvarande mellan de inmatade orden) osv. Vissa av alternativen har sina egna specifika inställningar. Dessutom är det möjligt att använda en ordbok med oviktiga ord, och programmet har redan en färdig lista över dessa ord, du kan också använda en ordbok med prioriterade ord för att söka (naturligtvis måste du fylla i den själv).
Här har vi i princip kort gått igenom alla huvuddragen i frassökning.
Låt oss gå vidare för att överväga funktionerna i detta program - leta efter liknande dokument. Utvecklarna hävdar att detta inte på något sätt är en enkel textsökning, det är just en "sökning efter liknande" - det är precis så det beskrivs överallt, men jaja, du kan kalla det vad du vill - huvudpoängen är . En snabb sökning på Internet kan snabbt avslöja att så kallad "liknande sökning" är en nyutveckling inom textanalysområdet. Detta system låter dig hitta texter som liknar semantiskt innehåll. Det roligaste var att efter att ha genomfört testsökningar visade det sig att teorin stämmer ganska väl överens med praktiken! Programmet söker faktiskt efter dokument med liknande innehåll och visar dem i en lista och sorterar dem efter procentandel av likhet.
Låt oss sedan titta på vad SearchInform (i synnerhet dess företagsversion SearchInform Corporate) erbjuder för att arbeta i ett företagsnätverk. Det finns två typer av applikationer: serversidan och användarsidan. Server del Den bearbetar automatiskt de angivna indexen och användare kan använda dem för sökning, beroende på de åtkomsträttigheter som tilldelats dem. Användare kan konfigureras automatiskt med konton Windows (i professionella termer, SearchInform använder NTFS Windows-autentisering) och manuellt (användare måste läggas till separat). Varje användare kan tillåtas eller nekas åtkomst till vissa index, och användare kan också kombineras i grupper. I allmänhet ligger SearchInforms inställningar för att arbeta på nätverket före Google när det gäller flexibilitet och Ishhound Server när det gäller bekvämlighet och enkelhet.
Officiell webbplats:
Distributionsstorlek: 14,7 Mb Jämförelse av indexeringshastigheter
Söksystem Indexeringstid Indexstorlek Bloodhound Prof Deluxe 4.5 38 timmar 46 minuter 19 GB Isys Desktop 7.0 6 timmar 13 minuter 7,9 GB DtSearch 7.0 6 timmar 3 minuter 8,6 GB Google Desktop Search Enterprise 8 timmar 17 minuter 4,5 GB Copernic Desktop Search * 10 timmar 51 minuter 7 GB SearchInform 1.5.02 3 timmar 17 minuter 4,4 GB * De flesta av documents.html och .txt som innehöll rysk text, var omöjliga att hitta, även om de var indexerade, förutom genom deras namn
Alla program är värda uppmärksamhet.
Baserat på tester och en noggrann granskning av varje program som presenteras i granskningen kan vissa slutsatser dras. Så, Google Desktop Search Copernic Desktop Search är ganska lämplig för den oerfarna användaren som ett heminformationssökningssystem. De klarar enkla frågor bra, överbelasta inte användaren med inställningar och är dessutom helt gratis. Googles försök att komma in på marknaden för företagssökmotorer är ännu inte särskilt motiverat: för att det ska fungera korrekt måste programmet vägas ytterligare moduler, och det är långt ifrån lätt att ställa in. Därför reserverar de självförklarande namnen Desktop Search, Copernic och Google nischen av "desktop" sökmotorer bakom sig.
Sant, mer kraftfulla lösningar - dtSearch, iSYS och SearchInform är inte heller idiotsäkra och erbjuder användarna deras "desktop"-versioner. Men till ett rimligt pris, till skillnad från gratisprogram från Google och Copernic. Självklart måste du betala för kraft, hastighet och funktionalitet. Men huvudfokus för utvecklarna av dtSearch, iSYS och SearchInform ligger naturligtvis på företagssektorn. Nätverk, funktionalitet, indexering och sökhastighet är det som skiljer dessa produkter från deras "konkurrenter". Baserat på testresultaten identifierades favoriten - SearchInform. Programmet ger möjlighet att söka efter liknande dokument, har de snabbaste indexerings- och sökhastigheterna och har en bra uppsättning funktioner.
Alexey Kutovenko
Professionell Internetsökning
Introduktion
Internetsökning är en viktig del av arbetet på Internet. Knappast någon vet med säkerhet det exakta antalet webbresurser på det moderna Internet. Hur som helst handlar det om miljarder. För att kunna använda den information som behövs vid ett givet ögonblick, oavsett för arbete eller underhållning, måste du först hitta den i denna ständigt påfyllda ocean av resurser. Detta är inte en lätt uppgift alls, eftersom informationen på det moderna Internet inte är strukturerad, vilket skapar problem med att hitta den. Det är ingen slump att de säregna "fönsterna" in i detta informationsutrymme Internet sökmotorer har blivit
Det är osannolikt att det bland internetanvändare kommer att finnas personer som aldrig har använt stora universella sökmotorer. Namnen Google, Yandex och ett par andra stora maskiner är på allas läppar. De klarar anmärkningsvärt bra med vardagliga sökuppgifter på Internet, och ofta försöker användare inte ens leta efter en ersättare. Samtidigt uppgår antalet sökmotorer på internet i vår tid till tusentals. Anledningarna till en sådan variation av alternativa maskiner har olika rötter. Vissa projekt försöker konkurrera direkt med globala marknadsledare genom noggrant arbete med nationella internetresurser. Andra erbjuder frågefunktioner som inte är tillgängliga från välkända sökmotorer. Ett betydande antal alternativa motorer är specialiserade på att söka efter ett visst ämnesområde eller en viss typ av innehåll, och uppnå imponerande resultat för att lösa dessa problem. Hur som helst, inkluderandet av sådana sökmotorer i en användares egen arsenal av sökverktyg på Internet kan förbättra kvaliteten avsevärt. Det finns dock en nyans här: du måste känna till sådana maskiner och kunna använda deras kapacitet.
Vi antar att läsarna av den här boken redan är ganska bekanta med söktekniker som använder universella sökmotorer. Det var så bra att de kände begränsningarna förknippade med deras användning. Troligtvis har sådana människor redan försökt leta efter och använda vissa ytterligare verktyg. Det tryckta ordet ignorerar inte ämnet Internetsökning: artiklar dyker upp med jämna mellanrum och böcker publiceras. Men deras hjältar är som regel desamma - flera ledande universella sökmotorer. Vår bok är annorlunda genom att den försöker täcka hela spektrumet av modern sök lösningar. Här hittar du beskrivningar och rekommendationer för att använda de bästa moderna tjänsterna som syftar till att lösa de vanligaste sökproblemen. Den här boken är till för personer som arbetar mycket på Internet och använder nätverket för att hitta den information de behöver - oavsett om det är affärer, studier eller hobby.
För att en internetsökning ska bli framgångsrik måste två villkor vara uppfyllda: frågorna måste vara välformulerade och de måste ställas på lämpliga platser. Det krävs med andra ord att användaren dels ska kunna översätta sina sökintressen till sökfrågans språk, dels god kunskap om sökmotorer, tillgängliga sökverktyg, deras fördelar och nackdelar, vilket gör att han kan välja de mest lämpliga sökverktygen i varje specifikt fall .
För närvarande finns det ingen enskild resurs som uppfyller alla krav på internetsökning. Därför, om du tar din sökning på allvar, måste du oundvikligen använda olika verktyg, och använda varje i det mest lämpliga fallet.
Det finns många sökverktyg tillgängliga. De kan kombineras i flera grupper, som var och en har vissa fördelar och nackdelar. Kapitlen i vår bok ägnas åt huvudgrupperna av moderna sökmotorer på Internet.
Kapitel 1, "Universella sökmotorer på internet," ägnas åt stora universella system för att hämta information på webben. Huvudfokus ligger på deras mest avancerade instrument, som vanligtvis faller under allmänhetens radar. En genomgång av kapaciteten hos kända maskiner ger oss en slags utgångspunkt och gör att vi tydligt kan föreställa oss tillämpningsområdet för alternativa söklösningar.
Kapitel 2, "Vertikal sökning", talar om system som är specialiserade på specifika ämnesområden eller specifika typer av innehåll.
Kapitel 3, "Metasearch", undersöker metasökmotorer som kan skicka en fråga samtidigt till flera sökmotorer på Internet och sedan samla in och bearbeta resultaten i ett enda gränssnitt.
Kapitel 4, "Semantiska och visuella sökmotorer på internet," är en översikt över experimentella system som erbjuder original användargränssnitt, såväl som intressanta metoder för bearbetning av frågor.
Kapitel 5, "Rekommendationsmaskiner," introducerar nyligen framväxande söktjänster, på engelska passande namnet "Discovery Engines", det vill säga "discovery machines". Med deras hjälp kan du bearbeta ett antal frågor som är för svåra för andra typer av sökmotorer på Internet.
Om ingen färdig produkt passar dig kan du skapa din egen sökmotor på Internet. Kapitel 6, "Personliga sökmotorer," ägnas åt att skapa sådana personliga maskiner.
Flera kapitel i vår bok ägnas åt att söka efter olika typer av onlineinnehåll. Kapitel 7, "Hämtning av bilder", introducerar aktuella trender för hämtning av bilder på Internet samt möjligheterna hos relaterade experimentella system. Kapitel 8, "Videosökning", ger en översikt över videosökverktygen för de ledande universella sökmotorerna på Internet, såväl som de bästa specialiserade systemen inom detta område.
Kapitel 9, "Hitta "dolt" innehåll," är en översikt över system som låter dig söka efter innehåll som "inte ses" av universella sökmotorer. Sådant "dolt" innehåll inkluderar till exempel torrents eller filer som finns på FTP-servrar och filvärdsajter.
Kapitel 10, "Search for Web 3.0", introducerar sökverktyg på Internet för data i Semantic Web-format.
Sökningen slutar inte med att bara få resultat från en eller annan sökmotor. Det sista kapitlet i vår bok, kapitel 11, "Hjälpprogram", ägnas åt verktyg för att bearbeta och spara resultat.
Innan du börjar en berättelse om specifika produkter är det vettigt att förstå klassificeringen av moderna sökverktyg på Internet, samt definiera de termer som ständigt finns på sidorna i vår bok.
De viktigaste sökverktygen på Internet kan delas in i följande huvudgrupper:
Sökmotorer;
Webbkataloger;
Hjälpresurser;
Lokala program för att söka på Internet.
De populäraste sökverktygen är sökmotorer – de så kallade sökmotorerna på Internet (Search Engines). De tre bästa ledarna på global nivå är ganska stabila - Google, Yahoo! och Bing. I många länder läggs deras egna lokala sökmotorer, optimerade för att arbeta med lokalt innehåll, till denna lista. Med deras hjälp kan du teoretiskt hitta vilket specifikt ord som helst på sidorna på många miljoner webbplatser.
Trots många skillnader fungerar alla sökmotorer på Internet enligt liknande principer och består ur teknisk synvinkel av liknande delsystem.
Den första strukturella delen av en sökmotor är specialprogram som används för automatisk sökning och efterföljande indexering av webbsidor. Sådana program brukar kallas spindlar eller bots. De tittar på webbsidors kod, hittar länkar på dem och upptäcker därigenom nya webbsidor. Det finns också alternativt sätt inkludering av webbplatsen i indexet. Många sökmotorer erbjuder resursägare möjligheten att självständigt lägga till en webbplats i sin databas. Men webbsidorna laddas sedan ner, analyseras och indexeras. De lyfter fram strukturella element, hittar nyckelord och bestämmer deras kopplingar till andra webbplatser och webbsidor. Andra operationer utförs också, vars resultat är bildandet av en sökmotorindexdatabas. Denna bas är den andra huvudelement någon sökmotor. För närvarande finns det ingen enda absolut komplett indexdatabas som skulle innehålla information om allt innehåll på Internet. Därför att olika sökmotorer Eftersom de använder olika sökprogram för webbsidor och bygger sitt index med olika algoritmer, kan sökmotorindexdatabaser variera avsevärt. Vissa webbplatser indexeras av flera sökmotorer, men det finns alltid en viss andel av resurserna som ingår i databasen för endast en sökmotor. Närvaron av en sådan original och icke-överlappande del av indexet i varje sökmotor gör att vi kan dra en viktig praktisk slutsats: om du bara använder en sökmotor, även den största, kommer du definitivt att förlora en viss procentandel av användbara länkar .
Introduktion
För närvarande ansluter Internet hundratals miljoner servrar som är värd för miljarder olika webbplatser och separata filer innehåller olika typer av information. Detta är ett gigantiskt arkiv med information. Det finns olika tekniker för att söka information på Internet.
Sök på känd adress. De nödvändiga adresserna hämtas från kataloger. Om du känner till adressen, skriv bara in den adressfältet Webbläsare.
Exempel 1. www.gov.ru är en server för ryska myndigheter.
Konstruera en adress av användaren. Genom att känna till systemet för att skapa internetadresser kan du skapa adresser när du söker efter webbplatser.
Till nyckelordet (namnet på ett företag, företag, organisation eller ett enkelt engelskt substantiv) måste du lägga till en tematisk eller geografisk domän, och du måste koppla din intuition.
Exempel 2. Kommersiella webbsidor:
www.samsung.com (SAMSUNG-företag),
www.mtv.com (MTV musiknyheter).
Exempel 3. Adresser till utbildningsinstitutioner:
www.ntu.edu ( National University USA).
Sökmotorer Internet
Särskilda system för informationssökning har utvecklats för att söka information på Internet. Sökmotorer har en vanlig adress och visas som en webbsida som innehåller specialverktyg för att organisera sökningar (söksträng, ämneskatalog, länkar). För att ringa en sökmotor, skriv bara in dess adress i adressfältet i webbläsaren.
Enligt statistiktjänsten LiveInternet.ru är fördelningen av sökmotorer i Ryssland ungefär som följer:
2) Google – 35,0 %
3) Sök Mail.ru – 8,3 %
4) Rambler – 0,9 %
Enligt metoden för att organisera information delas informationshämtningssystem in i två typer: klassificering (rubrikatorer) och ordbok.
Kategorier (klassificerare)- sökmotorer som använder en hierarkisk (träd)organisation av information. När du söker efter information, tittar användaren igenom tematiska rubriker och minskar gradvis sökfältet (om du till exempel behöver hitta betydelsen av ett ord måste du först hitta en ordbok i klassificeraren och sedan hitta det önskade ordet i det).
Ordbok sökmotorer– Det här är kraftfulla automatiska mjuk- och hårdvarusystem. Med deras hjälp visas (skannas) information på Internet. Uppgifter om platsen för den eller den informationen förs in i särskilda indexkataloger. Som svar på en begäran utförs en sökning enligt frågesträngen. Som ett resultat erbjuds användaren de adresser (URL) där det sökta ordet eller gruppen av ord hittades vid tidpunkten för skanningen. Genom att välja någon av de föreslagna länkadresserna kan du gå till det hittade dokumentet. De flesta moderna sökmotorer är blandade.
De mest kända och populära sökmotorerna:
Det finns system som är specialiserade på att söka informationsresurser inom olika områden.
https://my.mail.ru
https://ru-ru.facebook.com
https://twitter.com
https://www.tumblr.com
https://www.instagram.com osv.
Ämnessökmotorer:
Sök programvara:
Kataloger (tematiska samlingar av länkar med kommentarer):
http://www.atrus.ru
Regler för att verkställa förfrågningar
Varje sökmotors hjälpavsnitt ger information om hur man söker och hur man konstruerar en frågesträng. Nedan finns information om ett typiskt, "genomsnittligt" frågespråk.
Enkel begäran
Ange ett ord som definierar sökämnet. Till exempel, i sökmotorn Rambler.ru räcker det att ange: automation.
Dokument hittas som innehåller de ord som anges i begäran. Alla former av ryska ord känns igen som regel, bokstäver ignoreras.
Du kan använda tecknet "*" eller "?" i frågan. Tecken "?" i ett nyckelord ersätts ett tecken, i stället för vilket en bokstav kan ersättas, och "*"-tecknet är en sekvens av tecken.
Till exempel kommer frågan automatisk* att låta dig hitta dokument som innehåller orden automatisk, automation, etc.
Komplicerad begäran
Det finns ofta behov av att kombinera nyckelord för mer specifik information. I detta fall används ytterligare länkord, funktioner, operatorer, symboler, kombinationer av operatorer, separerade med parenteser.
Till exempel betyder frågan musik & (beatles beatles) att användaren letar efter dokument som innehåller orden musik och beatles eller musik och beatles.
Lista över sökservrar och kataloger
Adress Beskrivning www.excite.com Sökmotor med webbplatsrecensioner och guider www.alta-vista.com Sökserver, avancerade sökfunktioner tillgängliga www.hotbot.com Sökserver www.ifoseek.com Sökserver (lätt att använda) www.ipl.org Internet Publik library, ett folkbibliotek som verkar inom ramen för World Village-projektet www.wisewire.com WiseWire - organisation av sökning med hjälp av artificiell intelligens www.webcrawler.com WebCrawler - sökserver, lätt att använda www.yahoo.com CatalogWeb och gränssnitt för åtkomst av fulltextsökning på AltaVista-servern www.aport.ru Aport - ryskspråkig sökserver www.yandex.ru Yandex - ryskspråkig sökserver www.rambler.ru Rambler - ryskspråkig sökserver Hjälpresurser på Internet www.yellow.com Gula Sidorna Internet monk.newmail.ru Sökmotorer av olika profiler www.top200.ru Topp 200 webbplatser www.allru.net www.ru Katalog över ryska Internetresurser www.allru.net/z09.htm Utbildningsresurser www.students.ru Rysk studentserver www.cdo.ru/index_new.asp Distansutbildningscenter www.open.ac.uk UK Open University www.ntu.edu US National University www.translate.ru Elektronisk textöversättare www.pomorsu.ru/guide.library.html Lista över länkar till nätverksbibliotek www.elibrary.ru Vetenskapligt elektroniskt bibliotek www.citforum.ru Elektroniskt bibliotek www.infamed.com/psy Psykologiska tester www.pokoleniye.ru Webbplats för Internet Education Federation www.metod.narod.ru Utbildningsresurser www.spb.osi.ru/ic/distant Distansundervisning på Internet www.examen.ru Tentor och prov www.kbsu.ru/~book/ Lärobok i datavetenskap Mega.km.ru Uppslagsverk och ordböcker Professionell sökning efter information på Internet
Att söka information är en av de vanligaste och samtidigt svåraste uppgifterna som alla användare måste ställas inför på Internet. Men om för en vanlig medlem av onlinegemenskapen kunskap om metoder för effektiv informationsinhämtning är en önskvärd, men långt ifrån obligatorisk kvalitet, så är för informationspersonal förmågan att snabbt navigera på internetresurser och hitta de nödvändiga källorna en av de grundläggande kvalifikationerna färdigheter.
Orsaken till de svårigheter som uppstår när man söker information på Internet bestäms av två huvudfaktorer. För det första är antalet källor på Internet extremt stort. I slutet av 2001 angav de mest grova uppskattningarna en uppskattad siffra på 7,5 miljarder dokument som fanns på servrar runt om i världen. För det andra är utbudet av information på Internet inte bara kolossalt i volym, utan också extremt dynamiskt. Under den halv minut som du ägnade åt att läsa de första raderna i det här avsnittet dök ett hundratal nya eller ändrade dokument upp i det virtuella universum, dussintals flyttades till nya adresser och några upphörde att existera för alltid. Internet "sover aldrig", precis som vår planet aldrig "sover", längs vilken en våg av mänsklig affärsverksamhet kontinuerligt rullar i exakt enlighet med förändringen av tidszoner.
Till skillnad från en stabil och kontrollerad samling av dokument i ett bibliotek har vi på Internet att göra med en gigantisk och ständigt föränderlig informationsuppsättning, där sökandet efter data är en mycket, mycket komplex process. Situationen påminner ofta mycket om det välkända problemet med att hitta en nål i en höstack, och ibland förblir information av stort värde outtagna enbart på grund av svårigheten att hitta den.
De flesta användare av global datornätverk. Både amatörer och proffs använder ofta samma verktyg. Resultaten av sökningarna och tiden som läggs på dem varierar dock mycket.
Syftet med detta avsnitt är att bekanta dig i detalj med verktygen och metoderna för informationsinhämtning och utveckla stabila färdigheter för professionell sökning på Internet för alla typer av data: från texter i valfritt format, till video och animation.
Tematiskt material:Uppdaterad: 2021-09-12103583Om du upptäcker ett fel markerar du ett textstycke och trycker på Ctrl+Enter


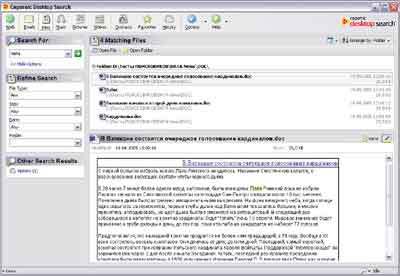
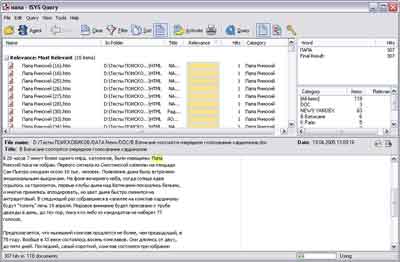








 Vilken kategori ska man välja för en sida på Facebook")